
آشنایی با NLTK، پردازش زبان طبیعی در پایتون
به پردازش زبان انسان به صورت خودکار یا نیمه خودکار، پردازش زبان طبیعی (NLP) گفته میشود. NLP دارای طیف گستردهای از برنامههای کاربردی در زمینههای مختلفی مانند بهداشت و سلامت، آموزش، تجارت و … است. پردازش زبان طبیعی در علوم کامپیوتر به حوزههایی مانند نظریه زبانها، تکنیکهای کامپایلر، تعامل انسان با کامپیوتر و یادگیری ماشین بسیار وابسته است. برای آشنایی بیشتر با NLP و کاربردهای آن میتوانید به این مقاله مراجعه کنید.
در این مقاله قصد داریم به صورت مختصر با یک platform بسیار جالب در پایتون برای پردازش زبان طبیعی آشنا شویم که با نام جعبه ابزار زبان طبیعی (NLTK) شناخته میشود. Natural Language Toolkit یا به اختصار NLTK یک platform رایج برای ساخت برنامههایی به منظور تجزیه و تحلیل متون مختلف است.
نصب NLTK
نصب NLTK با استفاده از ابزار pip در پایتون بسیار ساده است. با استفاده از دستور زیر میتوان بستهی مورد نظر را در سیستم نصب کرد.
pip install nltk
برای اطمینان از صحت نصب NLTK در سیستم، دستورات پایتون زیر را اجرا کرده و خروجی را مشاهده میکنیم.
import nltk nltk.__version__ # Output: '3.2.2'
همانطور که مشخص است این بسته به درستی در سیستم نصب شده که نسخهی آن نمایش داده شده است (ممکن است نسخهی NLTK در سیستم شما متفاوت با خروجی بالا باشد).
کار با NLTK
برای کار با NLTK لازم است تا در ابتدا مجموعهای از متون را دانلود کنیم. این مجموعه متون که با نام corpus نیز شناخته میشوند، از طریق NLTK قابل دستیابی هستند. یک corpus – که صورت جمع آن corpora است – در Wikipedia به صورت زیر تعریف میشود:
به مجموعهای خام از دادههای زبانیِ نوشتاری یا گفتاری گفته میشود که میتوان در توصیف و تحلیل زبان از آن بهره گرفت.
بنابراین میتوان گفت یک corpus، حجم وسیعی از فایلهای متنی را شامل میشود.
- توجه داشته باشید از آن جا که پردازش زبان طبیعی بر دو جنبهی متن و صوت زبان کار میکند، بنابراین یک corpus به صورت مجموعهای از فایلهای صوتی نیز میتواند وجود داشته باشد. ما در این مقاله تنها بر جنبهی متنی آن تمرکز میکنیم.
تمام corpusهای موجود در ابزار NLTK حجمی نزدیک به ۱۱GB دارد. شما میتوانید تمام آنها را دانلود کرده و یا فقط به دانلود مجموعه متون و بستههای مورد نیاز خود بپردازید. بدین منظور دو دستور زیر را در پایتون اجرا میکنیم.
import nltk nltk.download()
با اجرای دستورات بالا، پنجرهای به صورت زیر نمایش داده میشود که میتوانید بستههای مورد نیاز خود را در مسیر دلخواه دانلود کنید.
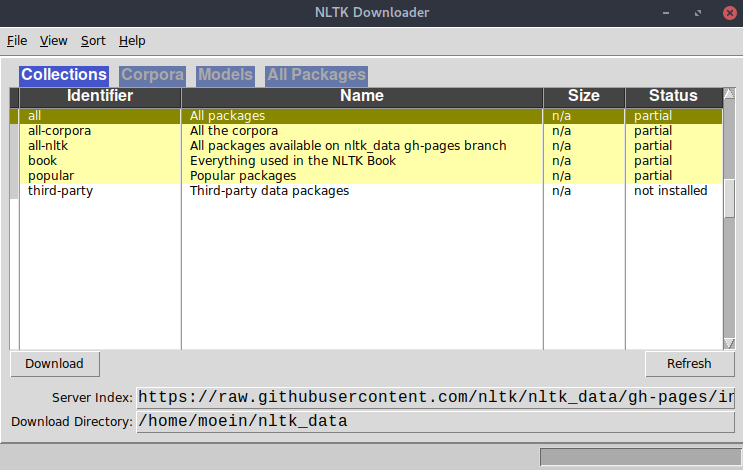
معمولا پس از نصب NLTK، برخی از corpus ها و فایلهای آن به صورت پیش فرض برای شما دانلود میشود. در صورتی که با اجرای دستورات نوشته شده در ادامهی این مقاله، بستهی NLTK خطایی مبنی بر عدم وجود فایل یا corpus مورد نظر برای شما نشان داد، میتوانید با استفاده از این محیط گرافیکی فایل مورد نیاز را دانلود کنید.
آشنایی با کلمات توقف (Stop Words)
گاهی اوقات لازم است تا به فیلتر سازی دادههایی بپردازیم که از اهمیت بالایی در متن برخوردار نیستند. با این کار کامپیوتر میتواند دادههای متنی را بهتر درک کند. بنابراین این کلمات برای ما معنای مشخصی نداشته و بهتر است تا آنها را از متون خود حذف نماییم. به چنین دادهها (کلمات) بی فایده در پردازش زبان طبیعی، کلمات توقف گفته میشود. NLTK مجموعهای از این کلمات توقف را برای ما فراهم کرده است. با استفاده از دستورات زیر میتوانیم این کلمات توقف را مشاهده کنیم.
from nltk.corpus import stopwords
print(stopwords.words('english'))
با اجرای دستورات بالا، مجموعهای از این کلمات در زبان انگلیسی نمایش داده میشود.

اما چطور میتوان این کلمات را از متن خود حذف نمود؟ قطعه کد زیر مثالی از نحوهی حذف کلمات توقف از یک جمله را نشان میدهد.
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
text = 'In this tutorial, I\'m learning NLTK. It is an interesting platform.'
stop_words = set(stopwords.words('english'))
words = word_tokenize(text)
new_sentence = []
for word in words:
if word not in stop_words:
new_sentence.append(word)
print(new_sentence)
# Output: ['In', 'tutorial', ',', 'I', "'m", 'learning', 'NLTK', '.', 'It', 'interesting', 'platform', '.']
در قطعه کد بالا، تابع word_tokenize در NLTK به تفکیک نشانهها و کلمات در جملهی موجود میپردازد. در واقع Tokenize کردن عملی است که در آن یک متن به کلمات، اصطلاحات، نمادها و یا دیگر عناصر معنی دار به نام نشانه (token) تفکیک میشود.
جست و جو در متن
در این مرحله قصد داریم تا در یک فایل متنی، کلمهی language را جست و جو کنیم (این فایل متنی را از اینجا میتوانید دانلود کنید). عمل جست و جو در این فایل به صورت زیر قابل انجام است.
import nltk
file = open('NLTK.txt', 'r', encoding='utf-8', errors='ignore')
read_file = file.read()
text = nltk.Text(nltk.word_tokenize(read_file))
match = text.concordance('language')
- برای آشنایی با چگونگی مدیریت فایلها در پایتون میتوانید به این مقاله مراجعه کنید.
پس از اجرای قطعه کد بالا، خروجی زیر نمایش داده میشود.
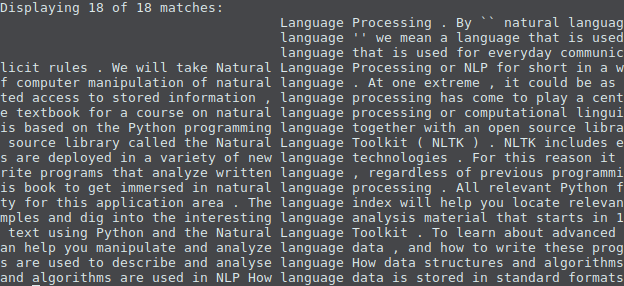
در این برنامه ابتدا عمل tokenize روی فایل خوانده شده صورت گرفته و سپس آن را به یک شی nltk.Text تبدیل نمودیم. تابع concordance کلمهی language را در متن پیدا کرده و آن را همراه با بخشی از متون اطراف آن برمیگرداند.
نحوهی استفاده از یک Corpus آماده
همان طور که پیش تر اشاره شد، NLTK شامل تعداد زیادی corpus آماده است که میتوان با آنها کار کرد. NLTK شامل قسمتی از مجموعه متون پروژهی گوتنبرگ میباشد که corpus مربوط به آن gutenberg نام دارد. برای آشنایی با پروژهی گوتنبرگ میتوانید به اینجا در Wikipedia مراجعه کنید. با استفاده از قطعه کد زیر میتوان مجموعه متون موجود در این پروژه را مشاهده نمود.
import nltk gutenberg_files = nltk.corpus.gutenberg.fileids() print(gutenberg_files)
با اجرای دستورات بالا، خروجی زیر نمایش داده میشود.

برای نمونه اگر بخواهیم تعداد کلمات موجود در فایل bryant-stories.txt را در این corpus بدست آوریم، میتوانیم دستورات زیر را اجرا کنیم.
import nltk
bryant_words = nltk.corpus.gutenberg.words('bryant-stories.txt')
print(len(bryant_words))
# Output: 55563
ما بر روی هر کدام از این فایلهای متنی میتوانیم اعمال مختلفی را انجام داده و با آنها تمرین کنیم تا کار با این ابزار را بهتر یاد بگیریم.
همانطور که مشاهده نمودیم، NLTK ابزاری قدرتمند برای پردازش زبان طبیعی در پایتون است که قابلیتهای فراوانی دارد. در این مقاله تنها به بررسی مختصر این ابزار پرداخته و با برخی از ویژگیهای سادهی آن آشنا شدیم. در صورتی که قصد دارید با قابلیتهای دیگر این ابزار برای پردازش زبان طبیعی آشنا شوید، میتوانید مرجع NLTK با نام Natural Language Processing with Python را بخوانید.
برای آشنایی با سایر کتابخانههای موجود برای پردازش زبان طبیعی، میتوانید این مقاله را بخوانید.
مطالب زیر را حتما مطالعه کنید

آشنایی با توابع در پایتون

راه اندازی Django به همراه Postgresql، Nginx و Gunicorn

آشنایی با حلقه ها در پایتون

آشنایی با رشته در پایتون

برنامه نویسی چند نخی در پایتون

دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.