
یادگیری ماشین به زبان ساده – بخش اول
سلام به شما دوستان و همراهان zerotohero. همان طور که قبلاً وعده داده بودیم قصد داریم آموزشهای بیشتر و کاملتری از مبحث یادگیری ماشین را پوشش دهیم. مبحثی که به جرئت میتوان گفت یکی از مهمترین تکنولوژیهای دهه آینده خواهد بود. حتی اگر در مورد آن هیچ چیزی نمیدانید باز هم خوش شانس هستید که این فرصت را برای یادگیری آن در این زمان دارید. مطمئن باشید در آینده از این علم بیشتر خواهید دید و شنید. با این سری مقالات همراه باشید تا به سادهترین شکل ممکن یاد بگیریم که یادگیری ماشین چیست و چطور میتواند به انسانها و همچنین کسب و کارها کمک کند.
این مقاله بخش اول از سری مقالات “یادگیری ماشین به زبان ساده” است. همچنین بخوانید: بخش دوم
قبل از این که شروع کنیم، قصد دارم از آدام گایتگی (Adam Geitgey) تشکر کنم که درخواست من برای گرفتن حق امتیاز ترجمه مقالاتش در سایت Medium را با روی خوش پذیرفت و حتی در ابتدای مقاله اولش لینک این صفحه را قرار داد.
. . .
میشنوید که مردم در مورد یادگیری ماشین صحبت میکنند ولی ایده خاصی در مورد این که واقعاً چه چیزی هست ندارید؟ آیا از این که هنگام بحث با دوستان و همکاران نمیتوانید نظری در این مورد بدهید خسته شدید؟ پس بیایید تغییرش بدهیم.
. . .
این راهنما مخصوص افرادی است که در مورد یادگیری ماشین کنجکاو هستند ولی ایدهای ندارند که از کجا شروع کنند. فکر میکنم افراد خیلی زیادی هستند که سعی کردند این مقاله ویکیپدیا را بخوانند، ولی چیز خاصی دستگیرشان نشد و بیخیال شدند، به این امید که یک نفر پیدا بشود و این مفاهیم را خیلی راحتتر به آنها آموزش بدهد. خب این همان چیزی است که میخواستید.
هدف این است که هر کسی به سادگی متوجه بشود، و این یعنی که مفاهیم به صورت کلی بیان خواهد شد. اما چه ایرادی دارد؟ اگر این مطالب باعث بشود حتی یک نفر بیشتر به یادگیری ماشین علاقمند شود، ما مأموریتمان را انجام دادهایم.
. . .
یادگیری ماشین چیست؟
یادگیری ماشین (Machine Learning) یعنی این که الگوریتمهایی وجود دارند که بدون نیاز به نوشتن کد اختصاصی برای مجموعهای از دادهها، میتوانند اطلاعات جالبی در مورد آنها به ما بگویند. به جای نوشتن کد، دادهها را به عنوان ورودی به این الگوریتمها میدهیم و الگوریتم بر مبنای دادهها خودش منطق خودش را میسازد.
برای مثال، یکی از این الگوریتمها، الگوریتم دستهبندی (classification) است که میتواند دادهها را در گروههای مختلفی قرار دهد. از همان الگوریتم دستهبندی که اعداد را در دست خط انسان تشخیص میدهد، میتوان برای دستهبندی ایمیلها به دو دسته هرزنامه و غیرهرزنامه نیز استفاده کرد، بدون این که لازم باشد حتی یک خط کد را تغییر دهیم. این همان الگوریتم است با این تفاوت که مجموعه دادههای آموزشی (training data set) متفاوتی به آن داده شده. بنابراین منطق دستهبندی نهایی نیز متفاوت خواهد بود.
در مورد مجموعه آموزشی که از این به بعد مجموعه train صدایش میکنیم، بعداً بیشتر توضیح میدهم، ولی فعلاً در همین حد بدانید که مجموعهای از دادهها است که الگوریتم را با آن آموزش میدهیم تا بدون این که لازم باشد ما کار خاصی انجام دهیم، خودش یاد بگیرد. هر چقدر این مجموعه بزرگتر باشد، یادگیری بهتر و دقیقتر انجام میشود.
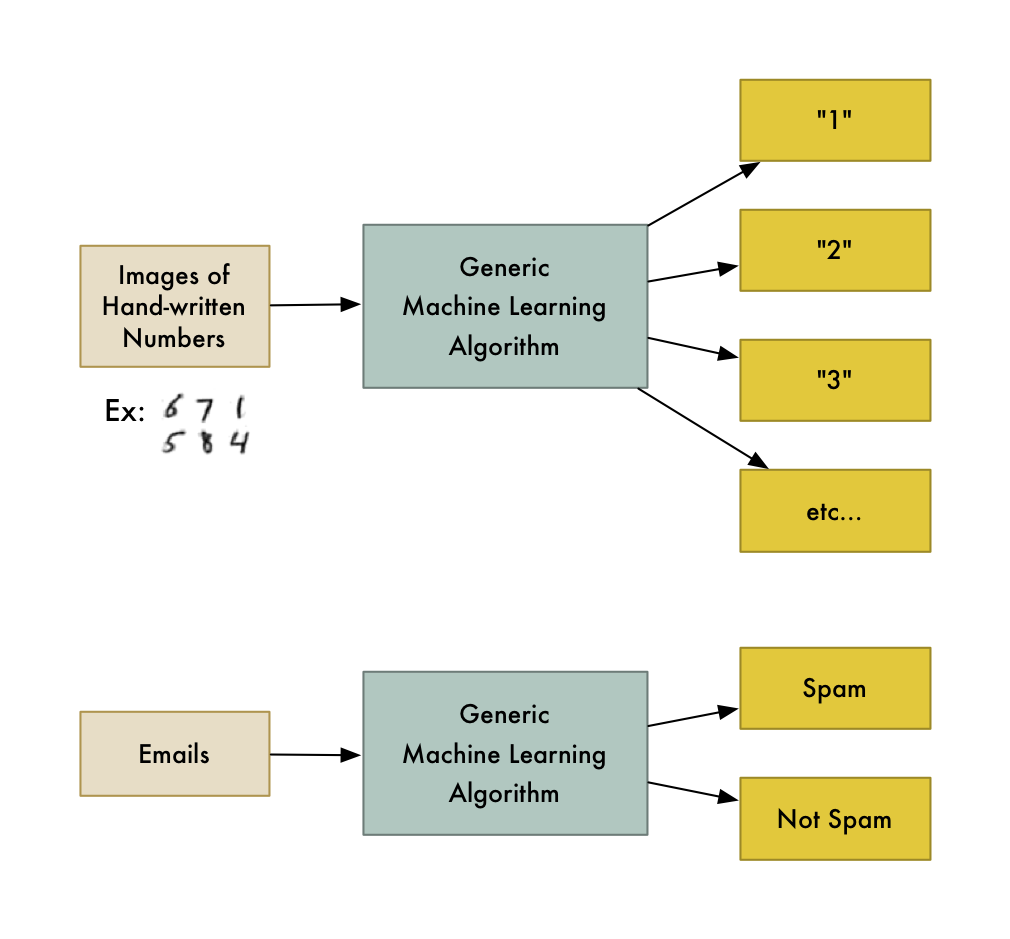
الگوریتم یادگیری ماشین یک جعبه سیاه است که میتوان از آن برای انواع مسائل دستهبندی استفاده کرد.
«یادگیری ماشین» اصطلاحی است که مثل یک چتر انواع این الگوریتمها را پوشش میدهد.
دو نوع مختلف الگوریتمهای یادگیری ماشین
اکثر الگوریتمهای یادگیری ماشین را میتوان در یکی از این دو دسته اصلی قرار داد: یادگیری بانظارت (Supervised Learning) و یادگیری بدون نظارت (Unsupervised Learning). تفاوت این دو ساده ولی بسیار مهم است.
یادگیری با نظارت
فرض کنید شما صاحب یک بنگاه معامله املاک هستید. کسب و کار شما در حال رشد است، بنابراین دو کارآموز استخدام میکنید تا به شما کمک کنند. اما مشکلی وجود دارد، شما با یک نگاه میتوانید ارزش یک ملک را تا حد خوبی تخمین بزنید، اما کارآموزهایتان تجربه شما را ندارند و نمیدانند چطور قیمتگذاری کنند.
برای کمک به کارآموزها (و شاید ایجاد فرصتی برای کمی استراحت بیشتر)، تصمیم میگیرید یک برنامه بنویسید که بر اساس اندازه، محله و دیگر مشخصات خانههای مشابهی که تا کنون فروخته شده، قیمت هر خانه را تخمین بزند.
سپس شما به مدت سه ماه اطلاعات هر خانهای که در نزدیکی شما فروخته میشود را یادداشت میکنید. اطلاعاتی مانند: تعداد اتاق خواب، مساحت، محلهای که خانه در آن قرار دارد و از همه مهمتر قیمتی که فروخته شده.
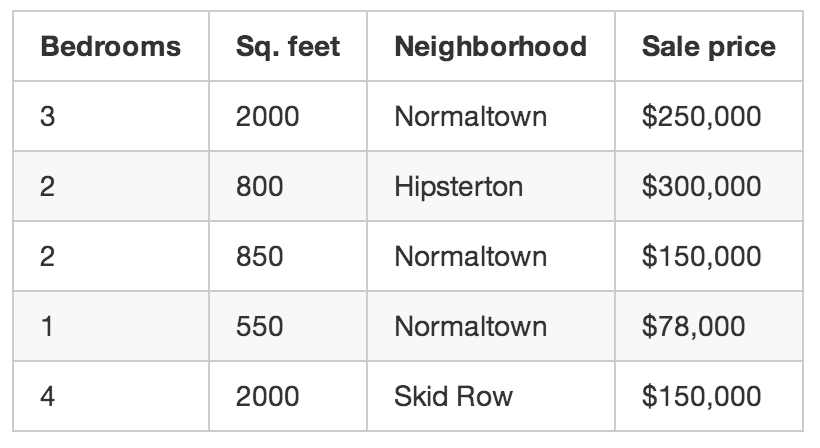
این همان مجموعه train ما است.
با استفاده از این مجموعه train، میخواهیم برنامهای بنویسیم که تخمین بزند هر خانه دیگری در اطراف شما چقدر ارزش دارد:

میخواهیم به کمک مجموعه train قیمت خانههای دیگر را پیشبینی کنیم.
به این نوع یادگیری، یادگیری بانظارت میگویند. ما میدانستیم هر خانه با چه قیمتی فروش رفته، یعنی به عبارت دیگر، ما جواب این مسئله را داشتیم. پس توانستیم برگردیم و منطق به کار رفته را نیز پیدا کنیم.
برای ساخت برنامه، مجموعه train را به عنوان ورودی به الگوریتم یادگیری ماشین میدهیم. الگوریتم در تلاش است تا بفهمد چه نوع ریاضیاتی به کار رفته تا این اعداد به دست بیاید.
این مشابه این است که در امتحان ریاضی جواب مسئلهها را داشته باشیم ولی عملگر بین اعداد مجهول باشد.
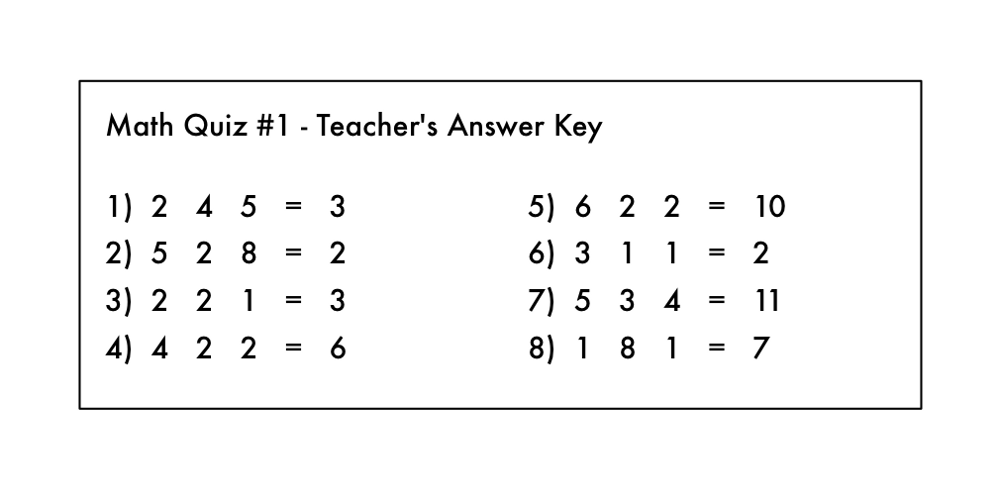
اوه نه! یک دانشآموز علامت عملگرها را از کلید تصحیح معلم پاک کرده!
آیا با استفاده از چیزی که موجود است میتوانید حدس بزنید سوالهای امتحان چه بوده؟ شما میدانید باید کاری با اعداد سمت چپ انجام دهیم تا به جواب سمت راست برسیم.
در یادگیری بانظارت، شما از کامپیوتر میخواهید تا این ارتباط را برای شما پیدا کند. و یک بار که ریاضیات به کار رفته برای این مسئله را پیدا کنید، میتوانید به هر مسئله دیگر از این نوع نیز پاسخ دهید!
یادگیری بدون نظارت
بیایید به مثال اصلی در مورد بنگاه املاک برگردیم. چه میشد اگر قیمت خانههای فروختهشده را نمیدانستیم؟ حتی اگر تنها چیزی که میدانیم اندازه، مکان و … هر خانه باشد، باز هم میتوانیم کارهای جالبی بکنیم. به این نوع یادگیری، یادگیری بدون نظارت میگویند.
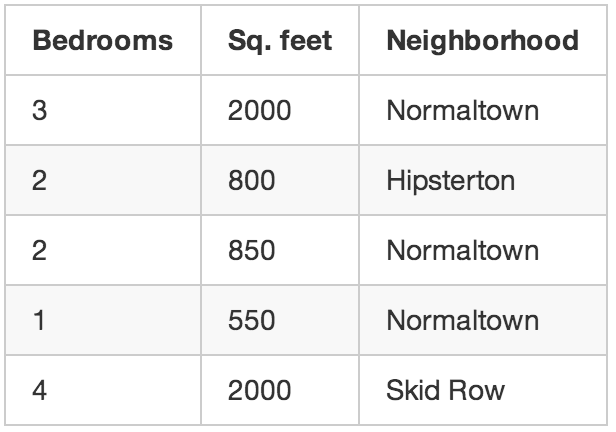
حتی اگر در تلاش برای پیشبینی یک عدد ناشناس (مثل قیمت) نباشید، باز هم میتوان با استفاده از یادگیری ماشین کاری کرد.
این مثل وقتی است که یک نفر کاغذی به شما بدهد که روی آن تعدادی عدد نوشته شده و بگوید: «من هیچ نظری ندارم که این عددها چه معنی و مفهومی دارند ولی شاید تو بتوانی الگو، گروهبندی یا چیزی پیدا کنی. موفق باشی!»
ولی با این دادهها چه کار میتوان کرد؟ برای شروع، میشود یک الگوریتم استفاده کرد که به صورت خودکار دستهبندیهای مختلف بازار را روی داده شما شناسایی کند. شاید شما متوجه شوید که خریداران خانه نزدیک به دانشگاه، خانههای کوچک با اتاقهای زیاد دوست دارند ولی خریداران خانه در اطراف شهر، خانههای سه خوابه ولی بزرگ دوست دارند. دانستن انواع مشتریها میتواند کمک کند بازاریابی بهتری داشته باشید.
یک کار جالب دیگر که میتوان انجام داد این است که به صورت خودکار دادههای پرت را شناسایی کنید. یعنی ببینید اطلاعات کدام خانه نسبت به بقیه خانهها تفاوت زیادی دارد و این شاید به این معنی باشد که با عمارتهای خیلی بزرگی سر و کار دارید که احتمالاً صاحبان آنها ثروتمند هستند و میتوانید حق کمیسیون بیشتری دریافت کنید.
چیزی که ما در ادامه این مقاله بر روی آن تمرکز میکنیم، یادگیری بانظارت است. البته نه به این معنی که یادگیری بدون نظارت در میزان استفاده و جالببودن چیزی کم از یادگیری بانظارت داشته باشد. در واقع، یادگیری بدون نظارت با پیشرفت الگوریتمها اهمیت زیادی پیدا کرده و در حال رشد است، به این دلیل که نیازی نیست دادههای آموزشی را با جواب درست برچسب بزنیم.
نکته: انواع دیگری از الگوریتمهای یادگیری ماشین نیز وجود دارد. ولی فعلاً برای شروع از پرداختن به آنها صرف نظر میکنیم.
جالبه، ولی آیا توانایی حدس زدن قیمت یک خانه، واقعاً یادگیری به حساب میآید؟
به عنوان یک انسان، مغز شما میتواند با هر وضعیتی مواجه شود و بدون دستورالعمل مشخص یاد بگیرد که چگونه با آن وضعیت برخورد کند. اگر برای مدت طولانی در کار فروش املاک باشید، به طور غریزی میتوانید «حس» کنید چه قیمتی برای یک خانه مناسب است، بهترین روش بازاریابی برای آن چیست، چه نوع مشتریانی به آن علاقمندند و غیره. هدف تحقیقات هوش مصنوعی قوی همین است که کامپیوتر نیز چنین مهارتی پیدا کند.
اما الگوریتمهای یادگیری ماشین فعلی هنوز اینقدر قوی نیستند و فقط وقتی کار میکنند که بر روی مسائل محدود و کاملاً مشخصی متمرکز باشند. شاید معنی بهتر برای یادگیری در حال حاضر «یافتن یک معادله برای حل مسئلهای مشخص بر اساس تعدادی داده نمونه» باشد.
متأسفانه این تعریف زیاد جالب نیست. برای همین ما از عبارت «یادگیری ماشین» استفاده میکنیم.
البته اگر شما ۵۰ سال آینده این متن را میخوانید احتمالاً الگوریتمهای هوش مصنوعی قوی کشف شده و این مقاله کمی عجیب به نظر میرسد. پس نیازی نیست ادامه آن را بخوانید و بهتر است به ربات خود بگویید به جای آن یک ساندویچ برای شما آماده کند، ای انسان آینده.
بیاید آن برنامه را بنویسیم!
میخواهیم برنامهای که گفتیم را بنویسیم. هدف تخمین قیمت یک خانه براساس اطلاعات فروش خانههای قبلی است. اما چگونه این کار را انجام دهیم؟ قبل از خواندن ادامه متن چند لحظه به آن فکر کنید.
اگر هیچ چیزی از یادگیری ماشین نمیدانستید احتمالاً تلاش میکردید تا قوانین سادهای برای تخمین قیمت یک خانه مانند این بنویسید:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# In my area, the average house costs $200 per sqft
price_per_sqft = 200
if neighborhood == "hipsterton":
# but some areas cost a bit more
price_per_sqft = 400
elif neighborhood == "skid row":
# and some areas cost less
price_per_sqft = 100
# start with a base price estimate based on how big the place is
price = price_per_sqft * sqft
# now adjust our estimate based on the number of bedrooms
if num_of_bedrooms == 0:
# Studio apartments are cheap
price = price — ۲۰۰۰۰
else:
# places with more bedrooms are usually
# more valuable
price = price + (num_of_bedrooms * 1000)
return price
اگر ساعتها وقت صرف این کد کنید احتمالاً در نهایت به برنامهای میرسید که تا حدی درست کار میکند، ولی هیچ گاه کامل و عالی نیست و با تغییر قیمتها همه چیز به هم میریزد.
بهتر نیست به کامپیوتر اجازه دهیم خودش نحوه پیادهسازی این تابع را پیدا کند؟ تا وقتی درست جواب بدهد چه اهمیتی دارد چگونه این کار را میکند:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = <computer, plz do some math for me> return price
یک راه برای نگاه کردن به این مسئله این است که فاکتور قیمت را مانند غذای خوشمزهای در نظر بگیریم که مواد اولیه برای تهیه آن تعداد اتاقها، مساحت و محله آن هستند. اگر میدانستید هر فاکتور به چه اندازه روی قیمت نهایی تأثیر میگذارد، احتمالاً میتوانستید نسبت دقیق مواد اولیه را برای تهیه این غذا بدست آورید.
این کار تابع اصلی شما (با آن همه if و else) را تا چیزی در این حد ساده میکند:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * .841231951398213 # and a big pinch of that price += sqft * 1231.1231231 # maybe a handful of this price += neighborhood * 2.3242341421 # and finally, just a little extra salt for good measure price += 201.23432095 return price
به اعداد جادویی که bold شدهاند توجه کنید. اینها وزن مواد اولیه هستند. پس کافی است وزنها را به صورت دقیق محاسبه کنیم تا تابع ما قیت نهایی را پیشبینی کند.
یک روش احمقانه برای پیدا کردن وزنها این است:
گام اول:
در ابتدا همه وزنها را برابر ۱.۰ قرار دهید:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * 1.0 # and a big pinch of that price += sqft * 1.0 # maybe a handful of this price += neighborhood * 1.0 # and finally, just a little extra salt for good measure price += 1.0 return price
گام دوم:
به ازای خانههایی که اطلاعات آنها را از قبل داریم، هزینه نهایی را با وزن گفته شده محاسبه کنید و ببینید چقدر با هزینه واقعی اختلاف دارد:
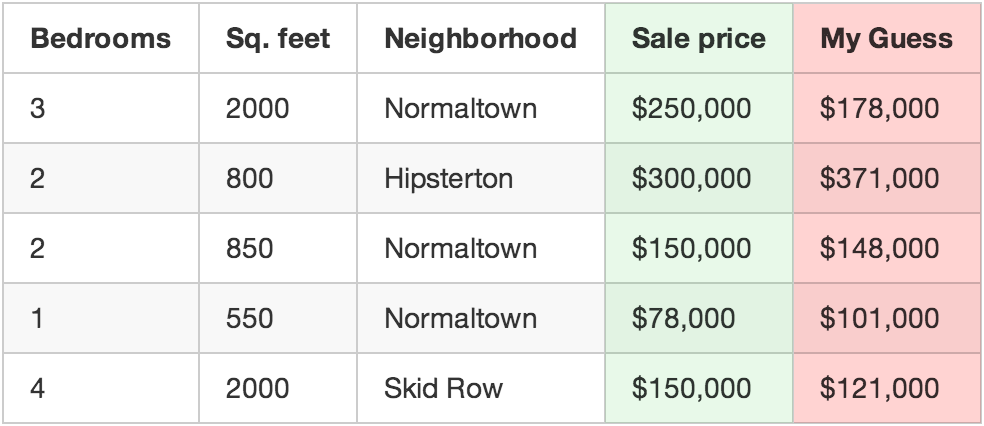
از تابعی که نوشتید برای تخمین قیمت هر خانه استفاده کنید.
برای مثال، اگر خانه اول به مبلغ ۲۵۰ هزار دلار به فروش رفته ولی تابع شما عدد ۱۷۸ هزار را تخمین زد، شما ۷۲ هزار دلار اختلاف (خطا) دارید.
حالا مربع میزان اختلاف را به ازای همه خانههای مجموعه train جمع بزنید. فرض کنید ۵۰۰ خانه در مجموعه شما وجود داشته و مجموعی که برای اختلافها به دست آوردید عدد ۸۶,۱۲۳,۳۷۳ دلار را نشان میدهد. این یعنی تابع شما در حال حاضر چقدر «اشتباه» است.
حالا، مجموع به دست آمده را بر ۵۰۰ تقسیم کنید تا میانگین اختلاف به ازای هر خانه مشخص شود. این مقدار میانگین، هزینه تابع شما است.
اگر بتوانید با تغییر وزنها، این هزینه را به صفر برسانید، تابع شما عالی کار خواهد کرد. این یعنی در همه شرایط قبلی تابع شما قیمت نهایی را کاملاً دقیق تخمین زده است. پس هدف ما همین است که با امتحان کردن وزنهای مختلف، هزینه تابع را تا کمترین حد ممکن کاهش دهیم.
گام سوم:
گام دوم را به ازای انواع ترکیبهای ممکن وزنها بارها و بارها تکرار کنید. وقتی به حالتی رسیدید که هزینه تابع به صفر نزدیک شد، شما مسئله را حل کردهاید!
زمان انفجار ذهن
خیلی راحت بود، مگر نه؟ خب در مورد کاری که انجام دادید فکر کنید. مقداری داده جمع کردید، به عنوان ورودی به الگوریتمی خیلی ساده دادید، و در نهایت به تابعی رسیدید که میتواند قیمت هر خانهای در اطراف شما را تخمین بزند.
اما در ادامه چند نکته را بررسی میکنیم که واقعاً میتواند ذهن شما را منفجر کند:
- تحقیقات در بسیاری از زمینهها در ۴۰ سال گذشته نشان دادهاند که این الگوریتمهای یادگیری عمومی مشابه کاری که انجام دادیم، در مواقعی که نیاز است قوانین مشخص ارائه شود، نسبت به انسان عملکرد بهتری دارند. حتی احمقانهترین روش یادگیری ماشین هم میتواند انسانهای متخصص را شکست دهد!
- تابعی که شما نوشتید واقعاً احمقانه بود. چون حتی نمیدانست واحد مساحت و اتاق خواب چیست! تنها چیزی که میدانست این بود که باید مقدار مشخصی از آن اعداد را با هم ترکیب کند تا به جواب درست برسد.
- احتمالاً شما هیچ ایدهای ندارید که چرا مجموعهای مشخص از وزنها درست کار میکند. بنابراین شما تابعی نوشتید که نمیدانید چطور کار میکند ولی میتوانید ثابت کنید که درست کار میکند!
- تصور کنید به جای مساحت و تعداد اتاقها، تابع تخمین شما آرایهای از اعداد را به عنوان ورودی میگرفت. برای مثال فرض کنید هر کدام از این اعداد میزان روشنایی یک پیکسل از یک تصویر گرفتهشده توسط دوربین نصبشده روی ماشین باشد، خروجی تابع را «میزان زاویه چرخش فرمان خودرو» نامگذاری کنید. به همین راحتی شما برنامه یک اتومبیل خودران را نوشتید!
جالبه، این طور نیست؟
اما بخش مربوط به «هر عدد ممکن را امتحان کنید» چه میشود؟
بله، البته که نمیشود هر ترکیب ممکن از وزنها را امتحان کرد. این کار به معنای واقعی کلمه تا ابد طول خواهد کشید زیرا هیچ وقت اعداد تمام نخواهند شد.
برای جلوگیری از این اتفاق، ریاضیدانها روشهای هوشمندانهای معرفی کردهاند که به کمک آنها میتوان به سرعت مقادیر مناسب وزنها را بدون امتحان کردن تعداد خیلی زیادی از اعداد به دست آورد. یکی از این روشها را در ادامه میبینیم:
ابتدا، معادله سادهای برای محاسبه هزینه در گام دوم مینویسیم:
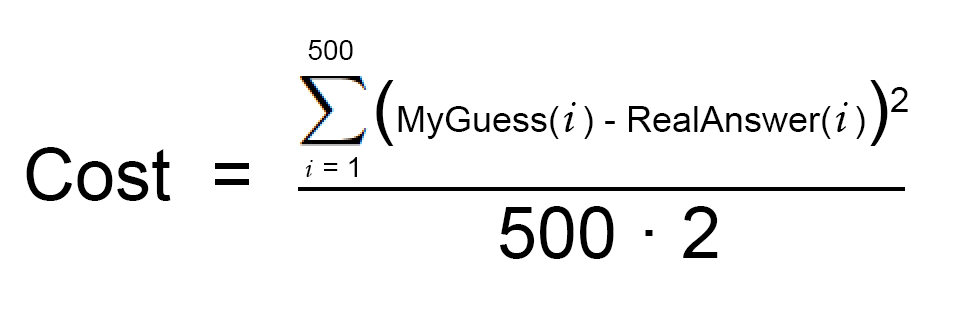
این همان تابع هزینه شما است.
حالا بیایید همین معادله را به صورت دیگری طبق ریاضیات یادگیری ماشین (که فعلاً از پرداختن به جزئیات آن صرف نظر میکنیم) بنویسیم:
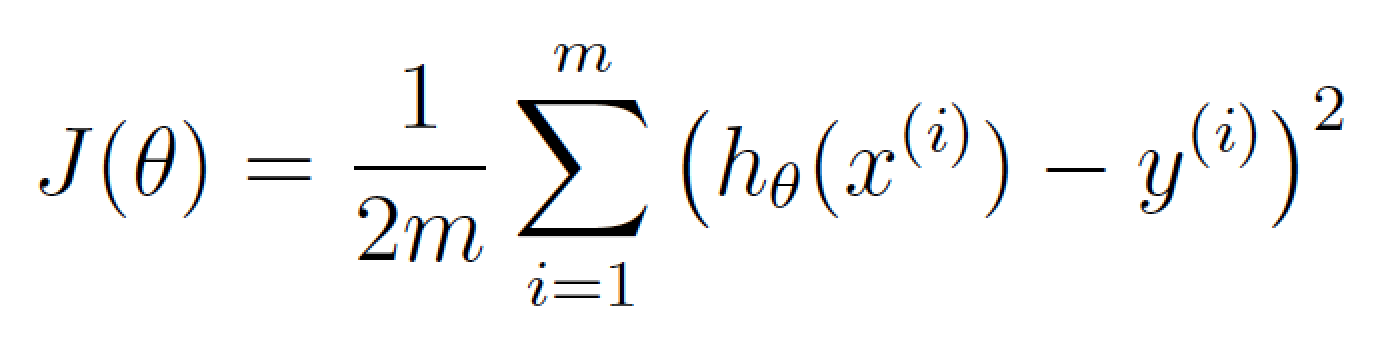
θ نماینده وزنهای فعلی شما است. و (j(θ یعنی هزینه به ازای این مجموعه از وزنها.
این معادله نشان میدهد تابع تخمین قیمت ما به ازای وزنهای فعلی تا چه حد اشتباه است.
اگر ما نمودار این معادله هزینه را به ازای تمام مقادیر وزنها برای تعداد اتاقها و مساحت را رسم کنیم، به نموداری شبیه به شکل زیر میرسیم:
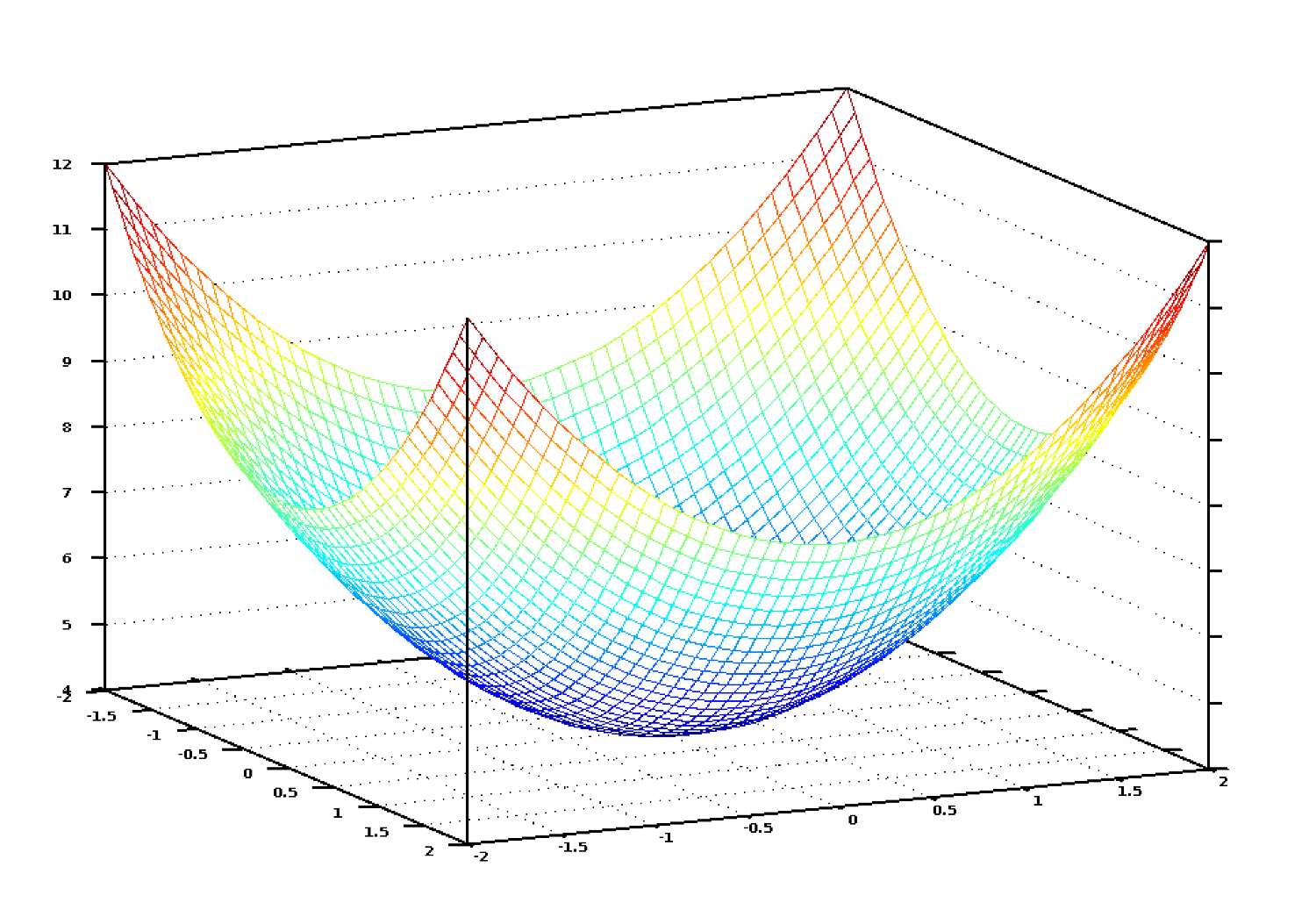
نمودار تابع هزینه شبیه به یک کاسه است. محور عمودی بیانگر هزینه میباشد.
در این نمودار، پایینترین نقطه به رنگ آبی جایی است که هزینه کمترین حد خود را دارد، پس میزان خطای تابع تخمین نیز کمینه خواهد بود. بالاترین نقاط جایی است که تابع ما بیشترین خطا را دارد. پس کافی است وزنها را به ازای نقطهای که کمترین ارتفاع دارد پیدا کنیم.
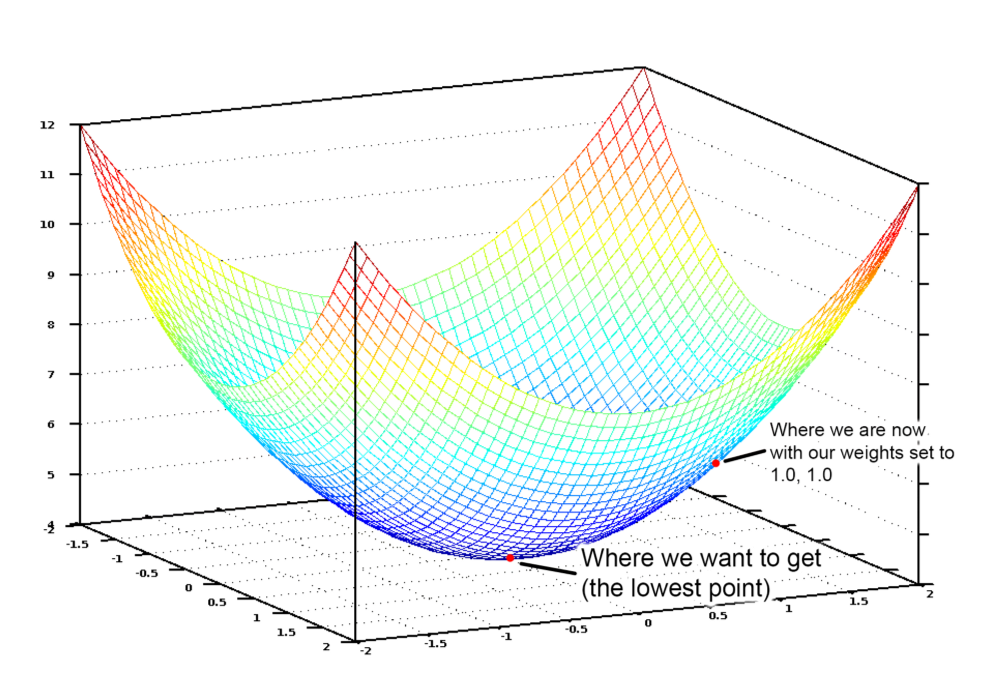
بنابراین کافی است ما وزنها را طوری تغییر دهیم که روی این نمودار به سمت پایین حرکت کنیم تا به پایینترین نقطه برسیم. به این ترتیب نیازی نیست اعداد زیادی را امتحان کنیم.
اگر چیزی از ریاضیات به یاد داشته باشید، میدانید که با مشتق گرفتن از یک تابع، شیب منحنی در هر نقطه به دست میآید. به این روش میتوان متوجه شد که روی نمودار به کدام سمت در حال حرکت هستیم.
پس اگر مشتق جزئی تابع هزینه را به ازای هر یک از وزنها محاسبه کنیم، میتوانیم مقدار آن را از هر وزن کم کنیم. و این یک قدم ما را به پایین منحنی نزدیک میکند. با ادامه دادن این کار، در نهایت به پایینترین نقطه نمودار میرسیم و بهترین مقادیر را به ازای وزنها خواهیم داشت. (اگر چیزی متوجه نشدید نگران نباشید و به خواندن ادامه دهید).
این خلاصهای بود از یکی از روشهای پیدا کردن بهترین وزنها برای تابع هزینه که گرادیان کاهشی دستهای نام دارد. اگر به این روش علاقمند شدید، جزئیات بیشتری در این جا پیدا خواهید کرد.
هنگامی که از کتابخانههای یادگیری ماشین جهت حل یک مسئله واقعی استفاده میکنید، تمام این مراحل خود به خود انجام خواهد شد و شما نیازی به محاسبه ندارید. اما با این حال بهتر است بدانید که چه اتفاقی میافتد.
درسته، برای راحتی بیشتر از بعضی مسائل صرف نظر کردیم
الگوریتم سه مرحلهای که توضیح دادم رگرسیون خطی چندمتغیره نام دارد. در واقع شما معادله خطی که از روی نقاط دادههای مربوط به خانه عبور میکند را تخمین میزنید. سپس از این معادله استفاده میکنید تا براساس محل قرارگیری نقاط، قیمت فروش خانههایی که قبلاً ندیدهاید را حدس بزنید. این ایده واقعاً قدرتمندی است که به کمک آن میتوانید مسائل “واقعی” را حل کنید.
روشی که با هم دیدیم ممکن است در مثالهای ساده جواب بدهد، ولی پاسخگوی همه مسائل نیست. یک دلیل آن این است که معمولاً قیمت خانهها به این سادگی از روی یک خط پیوسته به دست نمیآید.
اما خوشبختانه راههای زیادی برای حل این مشکل هست. الگوریتمهای یادگیری ماشین فراوان دیگری برای استفاده در دادههای غیرخطی داریم (مانند شبکههای عصبی یا SVMها به همراه kernel). همچنین راههای دیگری هم هست که اجازه میدهد از رگرسیون خطی هوشمندانهتر استفاده کنیم و اجازه میدهد خطوط پیچیدهتری را برازش یا به اصطلاح fit کنیم. با این حال در همه موارد، همچنان ایده اصلی این است که بهترین وزنها را پیدا کنیم.
همچنین، من از مشکل بیشبرازش (overfitting) صرف نظر کردم. این که وزنها را طوری تعیین کنیم که همیشه برای دادههای موجود در مجموعه اصلی جواب بدهد، کار سادهای است. اما ممکن است هیچ گاه برای خانههای جدید که اطلاعاتشان در مجموعه اصلی موجود نبود، کار نکند. برای این مشکل هم راه حلهایی وجود دارد (مانند Regularization و استفاده از مجموعه داده cross-validation). یادگرفتن چگونگی کنار آمدن با این مشکل یکی از اساسیترین گامهای پیادهسازی موفق الگوریتمهای یادگیری ماشین است.
به عبارت دیگر، در حالی که مفهوم اصلی بسیار ساده است، مهارت و تجربه نیاز است تا یادگیری ماشین را اعمال کنیم و نتایج مفید بگیریم. اما این مهارتی است که هر توسعهدهندهای میتواند یاد بگیرد!
آیا یادگیری ماشین جادو است؟
یک بار که ببینید تکنیکهای یادگیری ماشین به چه راحتی روی مسائل خیلی دشوار (مانند تشخیص دست خط) اعمال میشوند، حس میکنید راهی پیدا کردهاید که به شرط داشتن داده کافی هر مسئلهای را حل میکند. کافی است دادهها را وارد کنید و نگاه کنید کامپیوتر چطور جادوگرانه معادله متناسب با آن دادهها را کشف میکند!
اما یادتان باشد یادگیری ماشین تنها زمانی کار میکند که مسئله با دادههایی که دارید واقعاً قابل حل باشد.
برای مثال، اگر مدلی بسازید که قیمت هر خانه را بر اساس نوع گل و گیاه داخل هر خانه پیشبینی کند، هیچ وقت کار نخواهد کرد. چرا که هیچ ارتباطی بین قیمت خانه و نوع گیاه وجود ندارد. پس هر چقدر هم که تلاش کند، کامپیوتر هیچ گاه قادر به کشف ارتباط این دو و حل مسئله نخواهد بود.
تنها رابطههایی را میتوان مدلسازی کرد که واقعاً وجود داشته باشند.
پس به یاد داشته باشید، اگر یک انسان متخصص نمیتواند با دادهها به صورت دستی مسئله را حل کند، کامپیوتر هم احتمالاً نمیتواند. به جای این، روی مسائلی تمرکز کنید که انسان میتواند حل کند، ولی چقدر خوب میشود اگر کامپیوتر با سرعت و دقت خیلی بیشتری این کار را انجام دهد.
چطور در مورد یادگیری ماشین بیشتر یاد بگیریم؟
به نظر من، بزرگترین مشکل یادگیری ماشین این است که در حال حاضر بیشتر در دنیای آکادمیک و گروههای تحقیقاتی وجود دارد. بنابراین افرادی که دوست دارند بدون گرفتن تخصص صرفاً اطلاعاتی کلی کسب کنند، محتوای ساده و قابل درکی در اختیار ندارند. اما اوضاع روز به روز بهتر میشود.
دوره آموزشی رایگان آقای اندرو نگ (Andrew Ng) در سایت Coursera فوقالعاده است. من شدیداً توصیه میکنم از این جا شروع کنید. این دوره برای هر کسی با حداقل دانش از علوم کامپیوتر و ریاضیات مناسب است.
همچنین، میتوانید صدها الگوریتم یادگیری ماشین را با دانلود و نصب بسته SciKit-Learn برای پایتون ببینید و امتحان کنید.
. . .
هم اکنون میتوانید بخش دوم این مقاله را از وبسایت zerotohero دنبال کنید.
مطالب زیر را حتما مطالعه کنید

کتابخانههای برتر پایتون برای پردازش زبان طبیعی

رسم نمودار و مصور سازی دادهها در پایتون با استفاده از Matplotlib

آشنایی با سیستم های توصیه گر (Recommender Systems) و عملکرد آنها

آشنایی با Jupyter Notebook، ابزاری مفید برای دانشمندان داده

کاربرد هوش مصنوعی در مباحث پزشکی
13 Comments
Join the discussion and tell us your opinion.
دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.
سلام اگه اجازه بفرمایید از قسمت هایی از مطالب شما برای استفاده در یک ارائه کپی کنیم
این مجموعه با هدف توسعه دانش و مهارت شما ایجاد شده
با ذکر منبع می توانید مطالب سایت را در تمامی بستر ها ارائه و انتشار دهید
قهرمان دنیای خودت باش
خیلی عالی بود. ممنون
عااااااااااااااااااااااااااااااااااااااااااااااااااااااااااااااااااااااااااااااااالی بود
حتما حتما از این دست مقاله ها رو با مثال های عملی (کد نویسی) بیشتر کنید.
واقعا سایتتون عالیه عالی
اگر میشه راجع به overfitting هم همینقدر ساده و راحت توضیح بدید…متشکرم
ممنون از کامنت شما. حتماً در ادامه این سری از مقالهها در مورد overfitting هم به طور کامل توضیح خواهیم داد.
خیلی خیلی خیلی خوب بود…میتونم بگم کل چیزایی که تو یه ترم توی دانشگاه درس میدنو شما اینجا آورده بودید به زبان ساده
بنده واقعا استفاده کردم
ممنونم از شما
منتظر مقالات بعدی هستم
سلام. خوشحالم که این مقاله برای شما مفید بوده. به زودی قسمت دوم و ادامه این سری منتشر خواهد شد.
یعنی هم سایت عالی هم ترجمه عالی . چون خوب یادگرفتید خوب هم انتقال دادید. همیشه موفق باشید
عالی عالی عالی عالی؛ فقط میتونم بگم عالی
اصل مقاله خوب بوده و البته ترجمه عالی شما هم ارزش بسیاری دارد
منتظر بخش دومش هستم
به جرات میتونم بگم تا حالا مطلبی به این شیوایی؛ سادگی و گویایی نخونده بودم در این حوزه
سایر مطالب همگی خیلی ثقیل و آکادمیک هستند طوری که برای آدمی که اصلا آشنایی نداره ، فهمش ساده نیست.
دست مریزاد
از انرژی فوقالعادهای که با این کامنت به من دادی خیلی ممنونم میثم جان. علت انتخاب این سری مقالات هم دقیقاً همین بیان گویا و سادگی مطلب بود. تلاش میکنم هر چه زودتر بخشهای بعدی رو آماده کنم.
خیلی عالی بود.
مرسی