
یادگیری ماشین به زبان ساده – بخش دوم
در بخش اول دیدیم هنگامی که میخواهیم مسئلهای را حل کنیم، بدون این که لازم باشد کدی مخصوص به آن مسئله بنویسیم، یادگیری ماشین با استفاده از الگوریتمهای عمومی اطلاعات جالبی در مورد دادههای ما کشف میکند. (اگر هنوز بخش اول را نخواندهاید، همین الان این کار را بکنید!)
این بار قصد داریم به کمک یکی از این الگوریتمها، یک کار خیلی جالب انجام بدهیم. میخواهیم مراحل یک بازی کامپیوتری را طوری بسازیم که انگار توسط انسان طراحی شده است. برای این کار از یک شبکه عصبی استفاده میکنیم، مراحل موجود در بازی سوپر ماریو را به عنوان ورودی به آن میدهیم و مرحله جدیدی که خودبهخود ساختهشده است را به عنوان خروجی مشاهده خواهیم کرد!
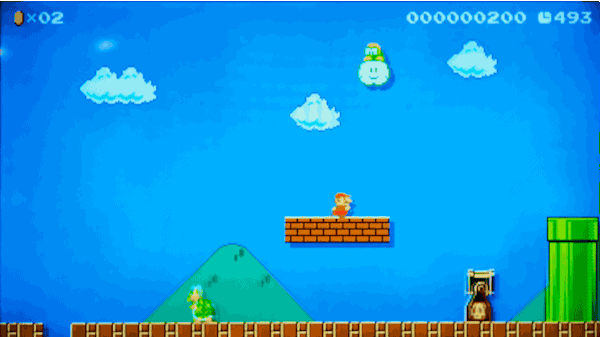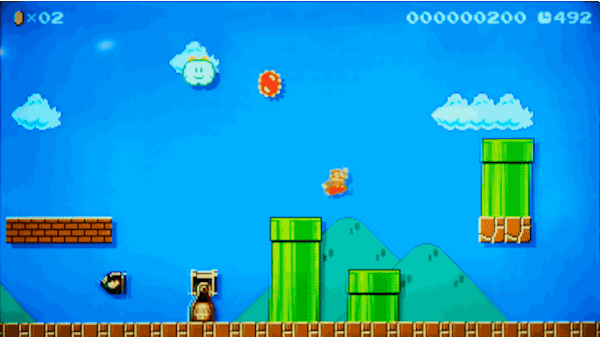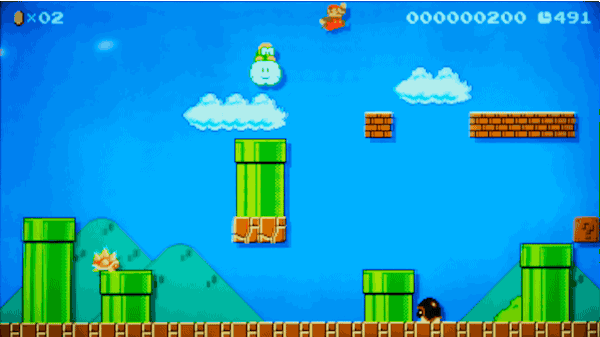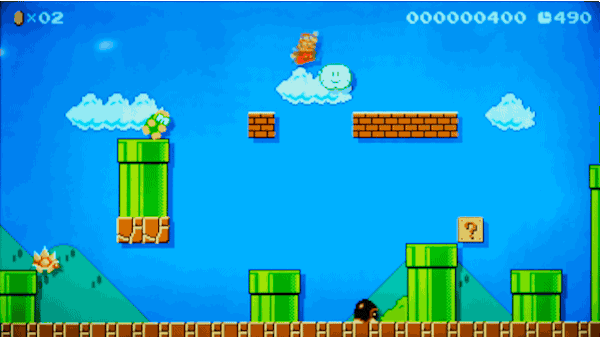
یکی از مراحلی که الگوریتم ما تولید خواهد کرد
دقیقاً مانند قسمت اول، این راهنما برای همه آنهایی است که در مورد یادگیری ماشین کنجکاوند اما نمیدانند از کجا شروع کنند. بنابراین هدف این است که این نوشته برای همه افراد قابل درک باشد و این یعنی از جزئیات دقیق خبری نیست و بسیاری از مفاهیم به صورت کلی بیان خواهد شد. اما مشکلی نیست، چون اگر این راهنما بتواند کسی را بیشتر به یادگیری ماشین علاقهمند کند ما مأموریتمان را انجام دادهایم.
چطور هوشمندانهتر حدس بزنیم؟
در بخش اول، ما الگوریتم سادهای نوشتیم که ارزش یک خانه را بر اساس مشخصاتش تخمین میزد. هر خانه مشخصاتی مانند جدول زیر داشت:

و در پایان به تابع تخمین ساده زیر رسیدیم:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * 0.123 # and a big pinch of that price += sqft * 0.41 # maybe a handful of this price += neighborhood * 0.57 return price
به عبارت دیگر، ما ارزش خانه را از ضرب هر کدام از مشخصهها در یک وزن و در نهایت جمع آنها بدست آوردیم.
به جای کد، اجازه دهید این تابع ساده را در قالب یک نمودار ساده ببینیم:
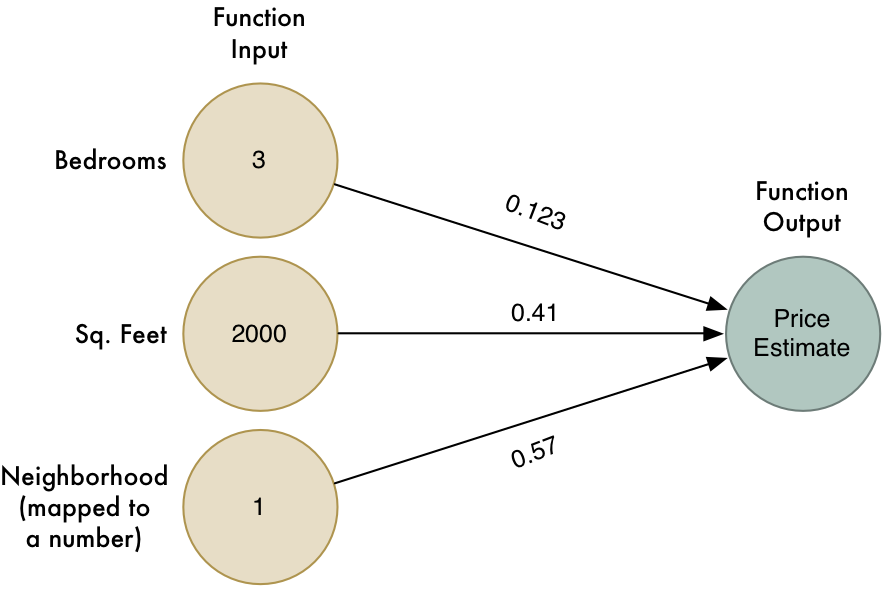
فلشها نمایانگر وزنهای تابع ما هستند.
اما این الگوریتم تنها برای مسائل سادهای که نتایج آنها رابطهای خطی با ورودی دارد قابل استفاده است. اما اگر حقیقت پشت قیمتگذاری خانهها در این حد ساده نباشد چه باید کرد؟ برای مثال، شاید این که خانه در کدام محله قرار دارد برای خانههای بزرگ و خانههای کوچک اهمیت زیادی داشته باشد، اما اصلاً برای خانههایی با اندازه متوسط اهمیت نداشته باشد. چنین جزئیات پیچیدهای (غیرخطی) را چطور میتوان در مدل ساختهشده قرار داد؟
برای این که در تخمین زدن باهوشتر عمل کنیم، میتوانیم این الگوریتم را چندین بار با وزنهای متفاوت اجرا کنیم و در نتیجه هر بار خروجی متفاوتی خواهیم داشت:
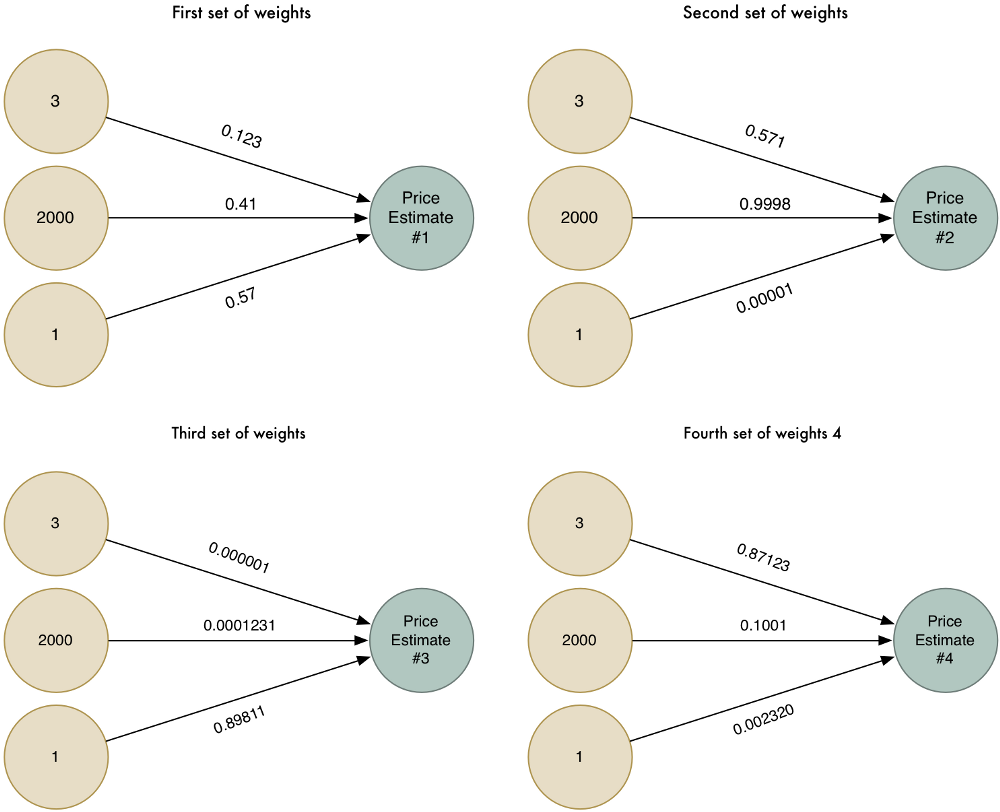
بیایید مسئله را به چهار روش مختلف حل کنیم.
اکنون چهار تخمین قیمت متفاوت داریم. بیایید این چهار تا را با هم ترکیب کنیم تا به یک تخمین نهایی برسیم. مجدداً همان الگوریتم را این بار با مجموعه جدیدی از وزنها اجرا میکنیم.
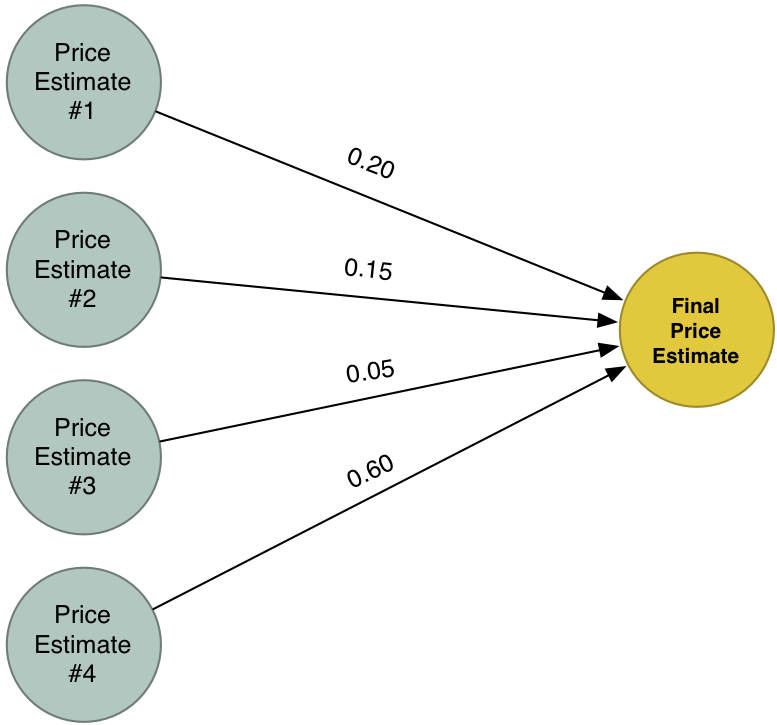
ابَرپاسخ ما به این مسئله، خروجی تخمینهای چهار تلاش قبلی را با هم ترکیب میکند. بنابراین، میتواند مدلهای پیچیدهتری را نسبت به مدل ساده اولیه پوشش دهد.
شبکه عصبی چیست؟
اگر نمودار کامل مراحلی که انجام دادیم را رسم کنیم به شکل زیر خواهد بود:
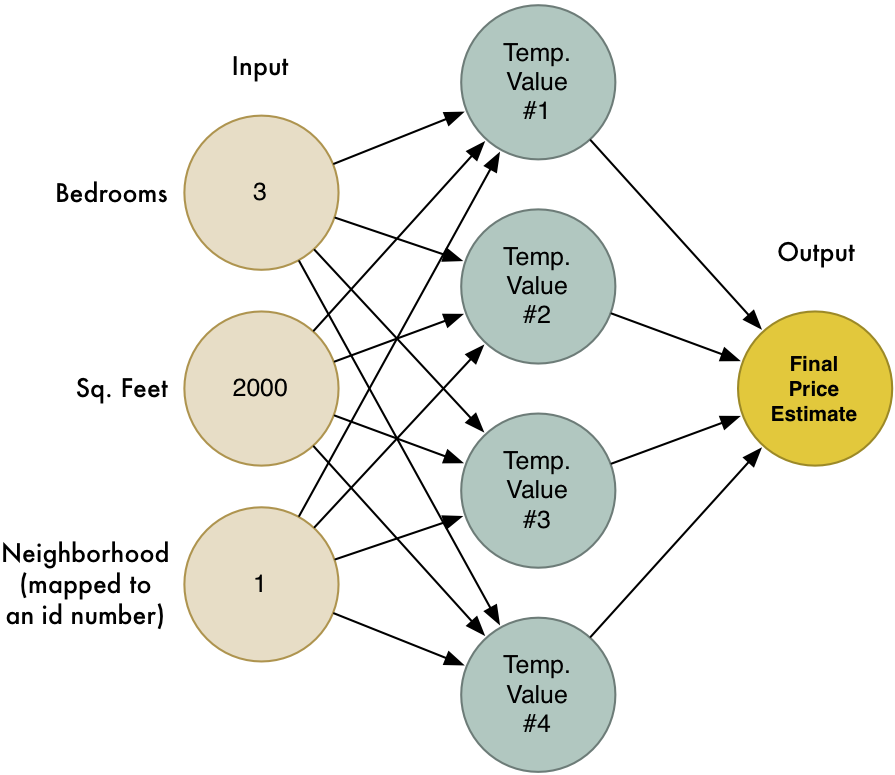
این نمودار یک شبکه عصبی است! هر نود (گره:node) میداند که چطور مجموعهای از ورودیها را بگیرد، به هر کدام وزن مشخصی اعمال کند، و یک مقدار خروجی محاسبه کند. اگر تعداد زیادی از این نودها را زنجیروار به هم متصل کنیم، میتوانیم به مدلی برسیم که توابع پیچیده را پوشش میدهد.
در این جا برای حفظ سادگی مطلب از جزئیات زیادی صرف نظر کردیم (مانند گسترش ویژگی و تابع فعالسازی)، اما مهمترین نکته این است که همین ایده ساده جرقههایی در ذهن ایجاد کرد:
- ما یک تابع تخمین ساده ساختیم که مجموعهای از ورودیها را میگیرد، آنها در مجموعهای از وزنها ضرب میکند و یک خروجی برمیگرداند. این تابع ساده را نورون مینامیم.
- با اتصال زنجیروار تعداد زیادی از این نورونهای ساده به همدیگر، میتوانیم به مدلهایی برسیم که نسبت به یک تک نورون توانایی پوشش توابع پیچیدهتری دارند.
درست مانند لگو! ما نمیتوانیم با یک قطعه ساده لگو چیز خاصی بسازیم، اما اگر به تعداد کافی از این لگوها داشته باشیم، با اتصال آنها به همدیگر میتوانیم هر چیزی بسازیم.

آیا یک شبکه عصبی میتواند حافظه داشته باشد؟
نوعی از شبکه عصبی که در مثال قبل دیدیم هر بار با ورودیهای یکسان، جواب یکسانی به عنوان خروجی ایجاد میکند. بنابراین حافظه ندارد یا به بیان برنامهنویسی، الگوریتمی بدون حالت (stateless) است.
در اکثر موارد (مانند تخمین ارزش خانه)، این دقیقاً همان چیزی است که میخواهیم. اما کاری که این الگوریتم قادر به انجام آن نیست، پاسخگویی به الگوهای داده در گذر زمان است.
تصور کنید من یک کیبرد به شما میدهم و از شما میخواهم یک داستان بنویسید. اما قبل از این که شروع کنید، وظیفه من این است که حدس بزنم اولین حرفی که با آن شروع میکنید کدام است. کدام یک از حروف الفبا را باید انتخاب کنم؟
من میتوانم از دانش زبانی استفاده کنم تا احتمال درست بودن حدس خودم را بالا ببرم. برای مثال، من میتوانم با بررسی لغات زبان فارسی ببینم اکثر کلمات با کدام حرف شروع میشوند. اگر من به داستانهایی که شما در گذشته نوشتهاید رجوع کنم، احتمالاً کلماتی وجود دارند که شما در آغاز داستان بیشتر از آنها استفاده کردهاید. به این ترتیب گزینههای احتمالی که من میتوانم به عنوان اولین حدس انتخاب کنم، کمتر میشود. وقتی که این دادهها را جمعآوری کردم، میتوانم از یک شبکه عصبی استفاده کنم تا احتمال شروع داستان شما با هر کدام از حروف الفبا مدلسازی کنم.
مدل ما به شکل زیر خواهد بود:

اجازه بدهید مسئله را کمی سختتر کنیم. فرض کنید به جای شروع داستان، هدف این باشد که تا هر کجای داستان را که نوشتهاید، بتوانیم حرف بعدی را حدس بزنیم. این مسئله به مراتب جالبتری است.
برای مثال، از چند کلمه اول یکی از کتابهای ارنست همینگوی به نام خورشید همچنان میدرخشد استفاده میکنیم:
Robert Cohn was once middleweight boxi
حرف بعدی چه خواهد بود؟
احتمالاً حدس شما حرف ‘n’ خواهد بود و احتمالاً کلمه مورد نظر boxing است. این را ما از جملاتی که تا به حال دیدهایم و دانش زبانیمان از کلمات متداول انگلیسی نتیجه گرفتیم. همچنین، کلمه قبلی یعنی middleweight به معنی میانوزن سر نخ خوبی است تا بدانیم احتمالاً موضوع به ورزش بوکس ربط دارد.
به عبارت دیگر، اگر دنباله حروفی که تا به این جا داریم را ارزیابی کنیم و از دانش قواعد زبان استفاده کنیم، حدس زدن حرف بعدی کار سختی نیست.
برای حل این مسئله توسط یک شبکه عصبی، لازم است برای مدل فعلیمان حالت (state) در نظر بگیریم. هر بار که از شبکه عصبی برای حدس زدن حرف بعدی سؤال میپرسیم، مجموعهای از محاسبات میانی داریم که میتوانیم در مرحله بعدی آنها را هم به عنوان بخشی از ورودی در نظر بگیریم. به این ترتیب، مدل ما پیشبینیهایش را بر اساس ورودی اخیراً مشاهدهشده انجام خواهد داد.
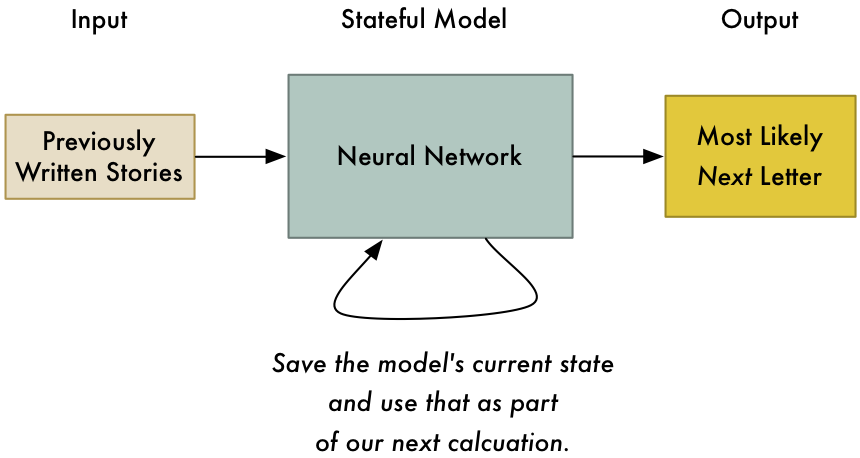
در نظرگرفتن حالت برای مدل به ما اجازه میدهد بتوانیم نه تنها اولین حرف داستان، بلکه در هر زمان اولین حرف از ادامه داستان را بر اساس حروف قبلی پیشبینی کنیم.
همین ایده ساده، درونمایه شبکههای عصبی بازگشتی (Recurrent Nerual Network) است. در واقع با این کار با هر بار استفاده از شبکه آن را آپدیت میکنیم. بنابراین پیشبینیها براساس آن چه اخیراً مشاهده شده بهروز میشود. اگر به اندازه کافی برای آن حافظه در نظر بگیریم، حتی قادر است الگوها را در گذر زمان مدل کند.
حدس زدن یک حرف به چه دردی میخورد؟
حدس زدن حرف بعدی در یک داستان ممکن است کار بیهودهای به نظر برسد. اما یک استفاده جالب آن قابلیت auto-predict در کیبرد گوشی موبایل است:
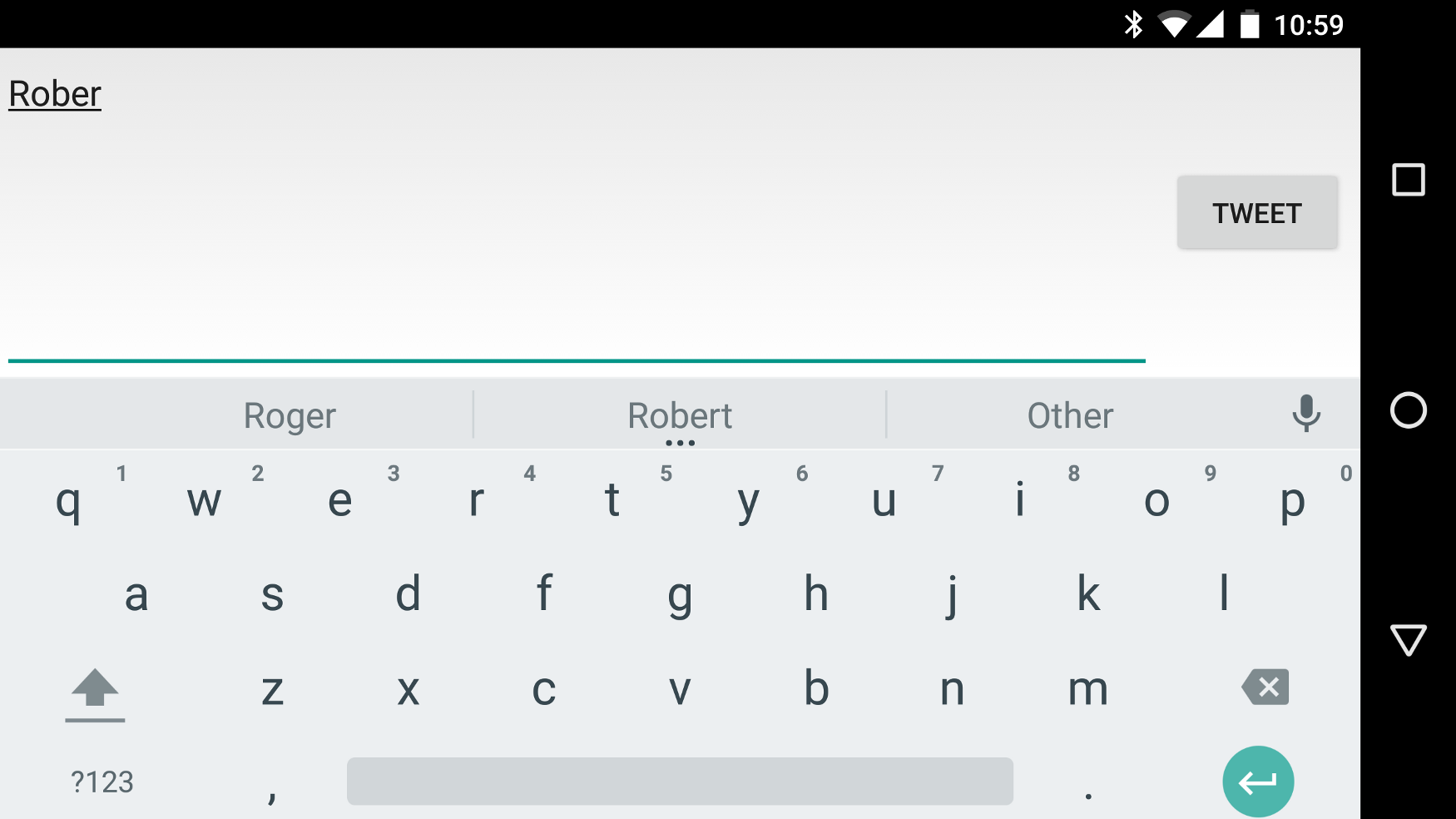
حرف بعدی احتمالاً ‘t’ خواهد بود.
اما به همین جا ختم نمیشود. میتوانیم از همین ایده استفاده کنیم و از کامپیوتر بخواهیم با حدس زدن حرف به حرف ادامه داستان، در نهایت یک داستان کامل را از ابتدا تا انتها بنویسد!
تولید یک داستان
دیدیم که چطور میتوان حرف بعدی جمله همینگوی را حدس زد. حالا بیایید یک داستان کامل را به سبک همینگوی بنویسیم.
برای این کار، از پیادهسازی شبکه عصبی بازگشتی که آندری کارپاتی نوشته استفاده خواهیم کرد. آندری یک محقق یادگیری عمیق در دانشگاه استنفورد است و همچنین یک متن عالی برای آشنایی با تولید متن به وسیله RNN نوشته است. تمامی کدها را در گیتهاب میتوانید ببینید.
مدل مورد نظر را براساس متن کامل خورشید همچنان میدرخشد خواهیم ساخت. این متن ۳۶۲۲۳۹ کاراکتر دارد که از ۸۴ حرف منحصر به فرد (شامل علائم نگارشی، حروف کوچک و بزرگ و غیره) تشکیل شده است. این مجموعه داده در مقایسه با مسائل دنیای واقعی بسیار کوچک است. برای تولید یک داستان خیلی خوب به سبک همینگوی در واقع لازم است چندین برابر این مقدار داده آموزشی داشته باشیم. اما برای این که کمی سرگرم شویم و با یک مثال عملکرد الگوریتم را ببینیم کافی است.
در اوایل آموزش RNN چندان در پیشبینی حروف خوب عمل نمیکند. این چیزی است که بعد از تنها ۱۰۰ بار تکرار آموزش به دست آمده است:
hjCTCnhoofeoxelif edElobe negnk e iohehasenoldndAmdaI ayio pe e h’e btentmuhgehi bcgdltt. gey heho grpiahe.
Ddelnss.eelaishaner” cot AAfhB ht ltny
ehbih a”on bhnte ectrsnae abeahngy
amo k ns aeo?cdse nh a taei.rairrhelardr er deffijha
میبینید که متوجه شده گاهی بین کلمهها فاصله قرار میگیرد، اما غیر از این موفقیت خاصی نداشته است.
بعد از ۱۰۰۰ بار تکرار، حاصل کمی امیدوارکنندهتر است:
hing soor ither. And the caraos, and the crowebel for figttier and ale the room of me? Streat was not to him Bill-stook of the momansbed mig out ust on the bull, out here. I been soms
inick stalling that aid.
“Hon’t me and acrained on .Hw’s don’t you for the roed,” In’s pair.”
“Alough marith him.”
مدل شروع به شناسایی الگوها در ساختار جملات ساده کرده است. در پایان جملات نقطه میگذارد یا حتی از علامت نقل قول استفاده میکند. تعداد کمی از کلمات معنیدار هستند اما تعداد بیشتری همچنان نامفهومند.
اما بعد از چندین هزار بار تکرار آموزش، به نظر خوب میرسد:
He went over to the gate of the café. It was like a country bed.
“Do you know it’s been me.”
“Damned us,” Bill said.
“I was dangerous,” I said. “You were she did it and think I would a fine cape you,” I said.
“I can’t look strange in the cab.”
“You know I was this is though,” Brett said.
“It’s a fights no matter?”
“It makes to do it.”
“You make it?”
“Sit down,” I said. “I wish I wasn’t do a little with the man.”
“You found it.”
“I don’t know.”
“You see, I’m sorry of chatches,” Bill said. “You think it’s a friend off back and make you really drunk.”
در این جا، الگوریتم الگوی ساده دیالوگهای کوتاه و مستقیم همینگوی را متوجه شده است. بعضی از جملات حتی منطقی به نظر میرسند.
برای مقایسه نگاهی به بخشی از متن واقعی کتاب داشته باشیم:
There were a few people inside at the bar, and outside, alone, sat Harvey Stone. He had a pile of saucers in front of him, and he needed a shave.
“Sit down,” said Harvey, “I’ve been looking for you.”
“What’s the matter?”
“Nothing. Just looking for you.”
“Been out to the races?”
“No. Not since Sunday.”
“What do you hear from the States?”
“Nothing. Absolutely nothing.”
“What’s the matter?”
حتی با وجود این که تمام تلاش ما حدس زدن یک کاراکتر در هر مرحله بود، الگوریتم ما توانست متن قابل قبولی با فرمت استاندارد تولید کند. به نظر من که خیلی جالب بود!
ما مجبور نیستیم متن را کاملاً از هیچ بسازیم. میتوانیم چند حرف اول را مشخص کنیم و از الگوریتم بخواهیم آن را کامل کند.
برای سرگرمی، میخواهیم برای کتاب جعلیمان جلد تهیه کنیم. برای تعیین اسم نویسنده و اسم جدید کتاب، حروف اولیه Er، He و The S را به عنوان ورودی به الگوریتم میدهیم:

کتاب واقعی در سمت چپ و کتاب بیمعنی تولیدشده توسط کامپیوتر در سمت راست قرار دارد.
بد نشد!
اما هیجانانگیزترین قسمت ماجرا این است که این الگوریتم میتواند هر الگویی را در دنبالهای از دادهها کشف کند. به سادگی میتوان دستور پختهای مشابه واقعی یا یک سخنرانی جعلی از اوباما تولید کرد. اما چرا خودمان را به زبان انسان محدود کنیم؟ این ایده را میتوان بر روی هر دنباله از انواع دادهها که از الگوی خاصی پیروی میکند امتحان کرد.
ساخت مراحل بازی سوپر ماریو به کمک کامپیوتر
در سال ۲۰۱۵، شرکت نینتندو ابزاری برای سیستم بازی Wii U منتشر کرد که توسط آن میتوان مراحل بازی سوپر ماریو را به صورت دستی طراحی کرد.
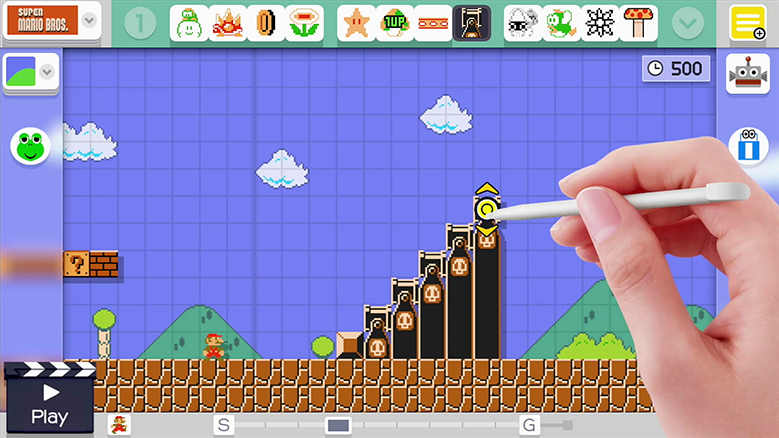
این برنامه به شما اجازه میدهد مراحل بازی سوپر ماریو را خودتان طراحی کنید و در اینترنت آپلود کنید تا دیگران از آنها برای بازی استفاده کنند. تمامی عناصر کلاسیک بازی، از جمله دشمنها، عناصر محیطی و غیره قابل استفاده هستند. مشابه یک مجموعه لگو که در اختیار افراد قرار گرفته تا به هر شکلی که کاربران میخواهند آنها را کنار هم بچینند.
آیا میتوانیم از همان مدلی که برای تولید متن جعلی به سبک همینگوی استفاده کردیم، برای ساختن مراحل بازی سوپر ماریو هم استفاده کنیم؟
ابتدا، لازم است مجموعهای از دادههای آموزشی تهیه کنیم. برای این کار از تمامی مراحل بازی اریجینال سوپر ماریو که در سال ۱۹۸۵ منتشر شد استفاده میکنیم:

این بازی ۳۲ مرحله داشت که ۷۰ درصد آنها محیط تقریباً مشابهی داشتند. پس از همینها استفاده میکنیم.
برای استخراج طراحی مرحلهها یک نسخه از بازی تهیه کردم و برنامهای نوشتم که ساختار طراحی مرحلههای بازی را از حافظه آن استخراج میکند. این بازی بیشتر از ۳۲ سال قدمت دارد و به اندازه کافی منابع در اینترنت موجود هست که شما را در این کار یاری کند. استخراج دادههای مربوط به مراحل بازی از حافظه آن خود یک تمرین برنامهنویسی جالب بود که توصیه میکنم امتحان کنید.
این اولین مرحله از بازی است (اگر بازی کرده باشید حتماً در خاطرتان هست):

سوپر ماریو – مرحله اول
اگر دقیقتر نگاه کنیم، میبینیم طراحی هر مرحله از مجموعهای از قطعات کوچکتر تشکیل شده است.

برای سادگی، هر کدام از این قطعات کوچک را با یک کاراکتر مشخص نمایش میدهیم:
-------------------------- -------------------------- -------------------------- #??#---------------------- -------------------------- -------------------------- -------------------------- -##------=--=----------==- --------==--==--------===- -------===--===------====- ------====--====----=====- =========================-
کاراکتر مربوط به هر قطعه به شرح زیر است:
- ‘-’ یک فضای خالی
- ‘=’ یک بلوک سنگی
- ‘#’ یک آجر شکستنی
- ‘?’ یک آجر حاوی سکه
و به همین ترتیب، به ازای هر قطعه از عناصر بازی یک کاراکتر به آن اختصاص میدهیم.
نمایش متنی مرحله بازی به شکل زیر خواهد بود:

با نگاه به فایل متنی، میبینید که اگر آن را خط به خط به صورت سطری بخوانیم الگوی خاصی مشاهده نمیشود:

با خط به خط خواندن، الگوی خاصی وجود ندارد. اکثر خطها کاملاً خالی هستند.
اما اگر به صورت ستونی به این فایل نگاه کنیم، الگوها خودشان را نشان میدهند.

با ستون به ستون خواندن، الگوها قابل مشاهده هستند. برای مثال هر ستون با ‘=’ به پایان میرسد.
پس برای این که الگوریتم ما این الگوها را شناسایی کند، دادههای ورودی را به صورت مجموعهای از ستونها انتخاب میکنیم. درک این که مؤثرترین روش نمایش دادههای ورودی چیست خود یکی از عناصر کلیدی در استفاده از الگوریتمهای یادگیری ماشین میباشد. این کار انتخاب ویژگی (feature selection) نام دارد.
برای آموزش این مدل، فایل متنی را ۹۰ درجه چرخاندیم.
-----------= -------#---= -------#---= -------?---= -------#---= -----------= -----------= ----------@= ----------@= -----------= -----------= -----------= ---------PP= ---------PP= ----------== ---------=== --------==== -------===== ------====== -----======= ---========= ---=========
آموزش مدل
دقیقاً همان طور که در مدل تولیدکننده متن همینگوی دیدیم، یک مدل با آموزش و تکرار ارتقاء مییابد.
بعد از کمی آموزش، مدل ما خروجی بیربطی تولید کرده است:
-------------------------- LL+<&=------P------------- -------- ---------------------T--#-- ----- -=--=-=------------=-&--T-------------- -------------------- --=------$-=#-=-_ --------------=----=<---- -------b -
البته تا حدی درست فهمیده که ‘-’ها و ‘=’ها زیاد تکرار میشوند. اما الگو را هنوز کشف نکرده است.
بعد از چندین هزار بار تکرار، بالاخره شکل معقولی به خودش میگیرد:
-- -----------= ----------= --------PP= --------PP= -----------= -----------= -----------= -------?---= -----------= -----------=
مدل تقریباً فهمیده است که هر خط باید طول یکسانی داشته باشد. همچنین بعضی از منطقهای موجود در طراحی بازی سوپر ماریو را نیز متوجه شده است، مانند این که لولهها همیشه دو بلوک عرض و حداقل دو بلوک ارتفاع دارند.
با بارها تکرار بیشتر آموزش، مدل میتواند دادههای کاملاً معتبری تولید کند:
--------PP= --------PP= ----------= ----------= ----------= ---PPP=---= ---PPP=---= ----------=
اگر خروجی یک مرحله کامل را از الگوریتم بگیریم و آن را به صورت افقی بچرخانیم حاصل به شکل زیر خواهد بود:

یک مرحله کامل که توسط مدل ما تولید شده است.
این دادهها کاملاً مناسب به نظر میرسند. به چند نکته باید توجه کنیم:
- یک Lakitu (غولی که روی ابر شناور است) در ابتدای مرحله در آسمان مشاهده میشود، دقیقاً مانند مراحل واقعی بازی.
- میداند که لولههای شناور روی هوا باید روی تکیهگاهی از بلوکهای سنگی قرار بگیرند.
- دشمنان در جایگاه درستی قرار دارند.
- هیچ مانعی سر راه بازیکن وجود ندارد که از پیشروی او جلوگیری کند.
- تقریباً حس یک مرحله واقعی از بازی را میتوان از تصویر زیر دریافت کرد. زیرا براساس مراحل واقعی بازی ساخته شده است.

دادههای ما هنگامی که وارد برنامه Super Mario Maker شد.
اسباببازی در مقابل کاربردهای دنیای واقعی
شبکه عصبی بازگشتی که برای آموزش مدل استفاده کردیم همان نوع الگوریتمی است که توسط شرکتهای دنیای واقعی برای حل مسائل دشوار مانند تشخیص کلام و ترجمه زبان استفاده میشود. چیزی که باعث میشود مدل ما به جای یک تکنولوژی پیشرفته بیشتر شبیه یک اسباببازی به نظر برسد این است که مدل ما از دادههای خیلی کمی بهدست آمده است. برای مثال مراحل کافی در بازی سوپر ماریو وجود ندارد که مدل ما از آنها برای ایجاد یک مرحله خیلی خوب از آنها استفاده کند.
اگر ما به صدها هزار مدل ساختهشده توسط کاربران نینتندو دسترسی داشتیم، میتوانستیم مدل خارقالعادهای بسازیم. اما نمیتوانیم، چون نینتدو به ما اجازه نمیدهد این دادهها را داشته باشیم. شرکتهای بزرگ دادههای خود را رایگان به کسی نمیدهند.
هر چه یادگیری ماشین در صنایع بیشتری اهمیت پیدا میکند، تفاوت میان برنامه خوب و برنامه بد در تعداد دادههایی است که برای آموزش مدل استفاده میشود. به همین خاطر است که شرکتهایی مثل گوگل و فیسبوک به طرز حریصانهای به دادههای شما نیاز دارند!
برای مثال، گوگل مدتی پیش TensorFlow را معرفی کرد. نرمافزاری متن باز که ابزارهایی برای کاربردهای یادگیری ماشین در مقیاس بزرگ فراهم میکند. این که گوگل چنین تکنولوژی مهمی را به رایگان در اختیار عموم قرار داد، اتفاق بسیار مهمی بود. این ابزار همان چیزی است که سرویس ترجمه گوگل از آن استفاده میکند.
اما بدون داشتن گنجینه عظیم دادههای گوگل در هر زبان، کسی نمیتواند رقیبی برای Google Translate بسازد. داده همان چیزی است که برتری گوگل را رقم زده است. دفعه بعدی که به تاریخچه مکانی Google Maps نگاه میکنید به این قضیه فکر کنید و خواهید دید که هر جایی که رفتهاید در دیتابیس گوگل ذخیره شده است.
در نهایت به یاد داشته باشید که در یادگیری ماشین، هیچ گاه تنها یک راه برای حل یک مسئله وجود ندارد. همچنین هیچ گاه نمیتوان یک الگوریتم را به عنوان بهترین راه حل انتخاب کرد. بسته به نوع مسئله، الگوریتمها میتوانند عملکرد متفاوتی داشته باشند. بینهایت راه پیش روی شما است که چگونه دادهها را پیشپردازش و از چه الگوریتمهایی برای یادگیری استفاده کنید. حتی گاهاً ترکیب چند روش مختلف ممکن است نتایج بهتری به همراه داشته باشد.
مطالب زیر را حتما مطالعه کنید

کتابخانههای برتر پایتون برای پردازش زبان طبیعی

رسم نمودار و مصور سازی دادهها در پایتون با استفاده از Matplotlib

آشنایی با سیستم های توصیه گر (Recommender Systems) و عملکرد آنها

آشنایی با Jupyter Notebook، ابزاری مفید برای دانشمندان داده

کاربرد هوش مصنوعی در مباحث پزشکی
4 Comments
Join the discussion and tell us your opinion.
دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.
مقاله بسیاری مفیدی بود
سلام. خوشحالم که مورد رضایت واقع شد. منتظر مقالههای بعدی باشید.
مقاله بسیار خوبی بود ممنونم از توضیحات کاملتون
سلام. خواهش میکنم. ممنون از نظر شما.