
آشنایی با Pandas، کتابخانهی تجزیه و تحلیل داده

پایتون زبانی عالی برای انجام تجزیه و تحلیل دادهها است، که عمدتا به دلیل اکوسیستم فوقالعاده بستههای (packages) آن میباشد. Pandas یکی از این بستههاست، که تجزیه و تحلیل دادهها را آسان میکند. طبق سایتِ pandas :
pandas کتابخانهای متن باز برای پایتون است، که امکان ارائه ساختارهای دادهای با کاراییِ بالا برای تجزیه و تحلیل دادهها را میدهد.
این کتابخانه به دلیل داشتن ساختارهای دادهای مناسب برای تمیز کردن دادههای خام (دادههایی که از منبع به دستِ کاربر میرسد) و ابزارهایی برای پر کردن دادههای از دست رفته، به شدت میان دانشمندان داده محبوب شده است.
نصب Pandas
ساده ترین روش برای نصب pandas، استفاده از Anaconda است. Anaconda توزیعی برای پایتون است، که شامل بیش از ۴۰۰ بسته محبوب برای ریاضیات، مهندسی، تجزیه و تحلیل دادهها و غیره میباشد. برای دانلود این توزیع به صفحه دانلود آن مراجعه کنید و مطابق سیستم عامل خود آن را دانلود و نصب کنید.
روش دیگر نصب pandas از طریق pip است. در خط فرمان عبارت زیر را وارد کنید:
pip install pandas
ساختار دادهای Pandas
در pandas سه نوع ساختار دادهای وجود دارد. نوع اول سری (Series) است، که یک بعدی است.
نوع دیگر که پراستفادهترین است، DataFrame نامیده میشود. DataFrame دو بعدی بوده و از سطر و ستون تشکیل شده است. DataFrame را میتوان همانند جدول پایگاه داده در نظر گرفت که ستونهای آن، ویژگیها و هر کدام از سطرهای آن، رکوردی از آن جدول باشد.
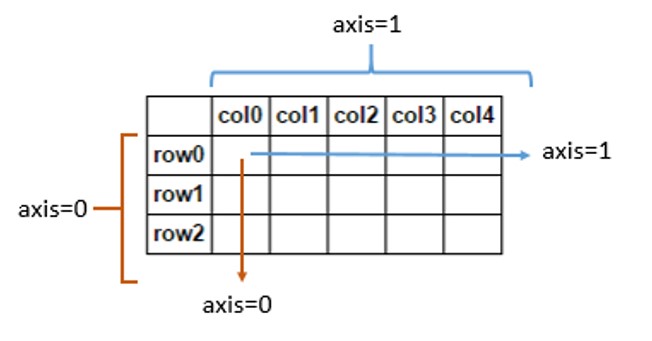
نوع دیگر از ساختار دادهای Panel میباشد، که از سه بعد به بالا را پوشش میدهد.
ساخت Series
اولین قدم، شامل کردنِ کتابخانه pandas در برنامه است. این کار را با قطعه کد زیر انجام میدهیم:
import pandas as pd
برای راحتیِ کار از مخفف pandas یعنی pd استفاده میکنیم.
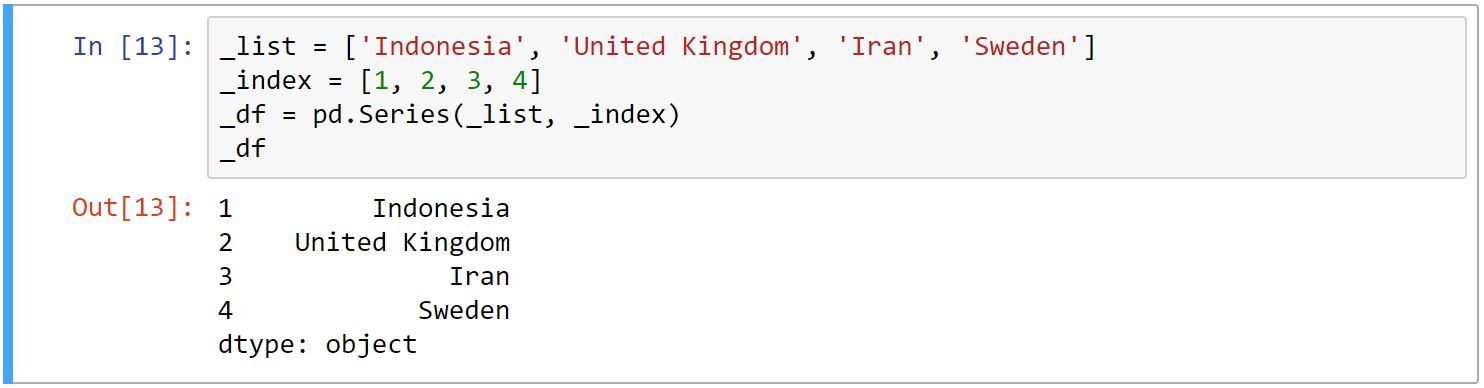
برای ساخت Series از متد ()Series استفاده میکنیم. به دلیل تک بعدی بودنِ Series، مقادیری که میدهیم باید در یک بعد باشد. پس از لیست کمک میگیریم و آن را به عنوان اولین آرگومان به آن میدهیم. آرگومان دوم نامِ index-ها میباشد، که اگر مشخص نشود، به صورت پیشفرض از ۰ شروع میشود. بعد از تعریف کردن لیستِ مقادیر و index-ها، آنها را به متد ()Series میدهیم و خروجی را دریافت میکنیم.
_list = ['Indonesia', 'United Kingdom', 'Iran', 'Sweden'] _index = [1, 2, 3, 4] _df= pd.Series(_list, _index) print(_df)
و خروجی به صورت زیر میشود:
- برای راحتیِ کار تمامی کدها در Jupyter Notebook نوشته شده است.
ساخت DataFrame
برای ساخت DataFrame بعد از شامل کردنِ کتابخانه pandas، از متد DataFrame کمک میگیریم. به دلیل دو بعدی بودنِ DataFrame، میتوان از دیکشنری کمک گرفت. کلیدهای دیکشنری به عنوان ستونها و مقادیر آنها به عنوان سطرها میباشند. قابلِ ذکر است که برای مقادیرِ دیکشنری از لیست استفاده میکنیم.
_dict = {'Country':['Indonesia', 'United Kingdom', 'Iran', 'Sweden'],
'Abbr':['ID', 'UK', 'IR', 'SE']}
_df = pd.DataFrame(_dict)
print(_df)
بعد از اجرایِ کد بالا، خروجی زیر را خواهیم داشت:
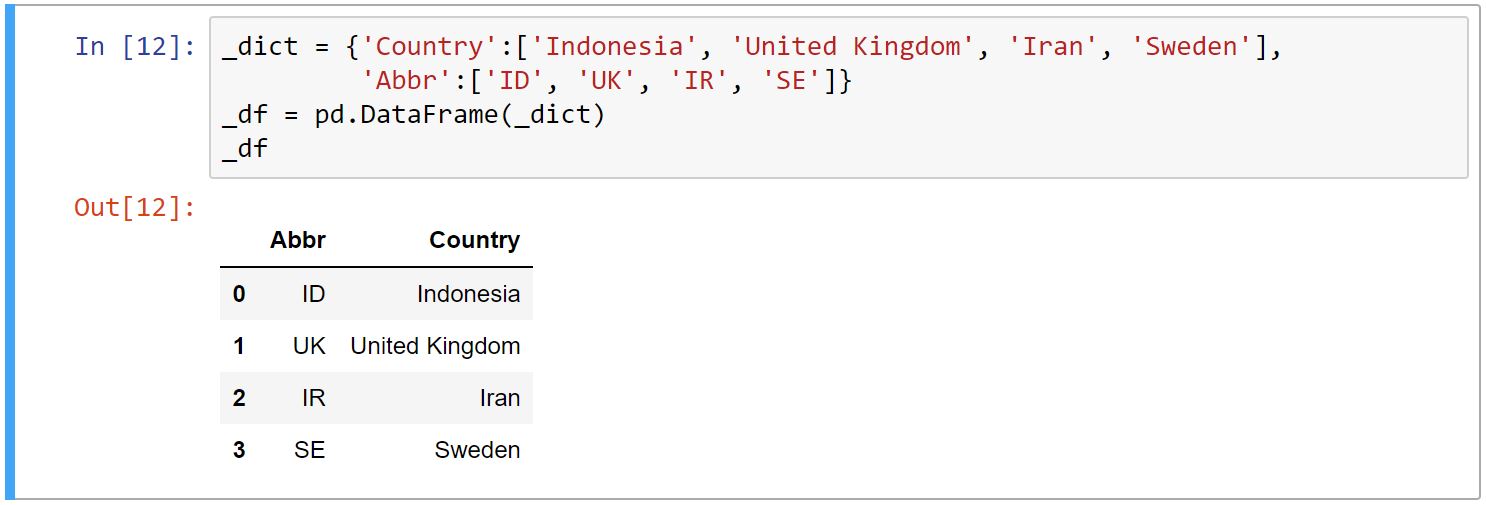
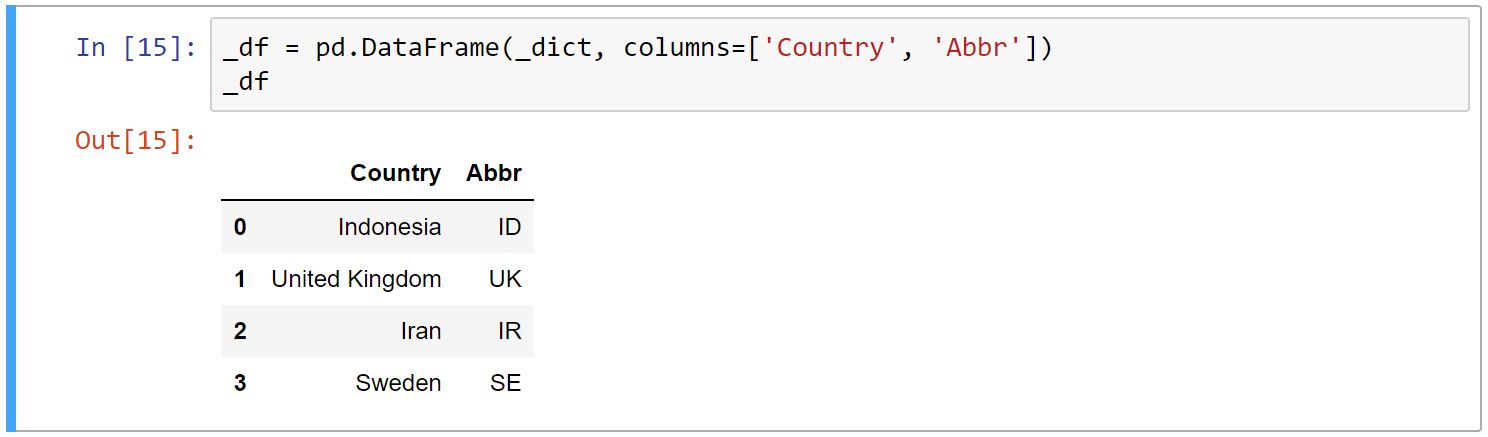
به دلیل اینکه DataFrame ستون ها را در دیکشنری به ترتیب حروف الفبا میخواند، ستون Abbr اول آمده است. برای اینکه ترتیبِ ستونها را مشخص کنیم، لیستی از ستونها را با ترتیبی که مد نظرِ ماست، به عنوان آرگومان به متد DataFrame میدهیم.
_df = pd.DataFrame(_dict, columns=['Country', 'Abbr'])
و خروجی به شکل زیر میشود:
توابع DataFrame
در ادامه کار با مجموعه داده zerotohero_dataframe کار خواهیم کرد. اطلاعات این DataFrame با استفاده از random تولید شده است.
-
Head و Tail
توابع ()head و ()tail به ما این امکان را میدهند که نمونهای از داده خود را ببینیم. head اولِ دادهها و tail آخرِ دادهها را نمایش میدهد. تعدادِ پیشفرضِ نمایش دادهها ۵ میباشد. اگر بخواهید تعداد دلخواهی از نمونهها را ببینید، اولین آرگومانِ این توابع را عدد مد نظر خود را میدهیم.
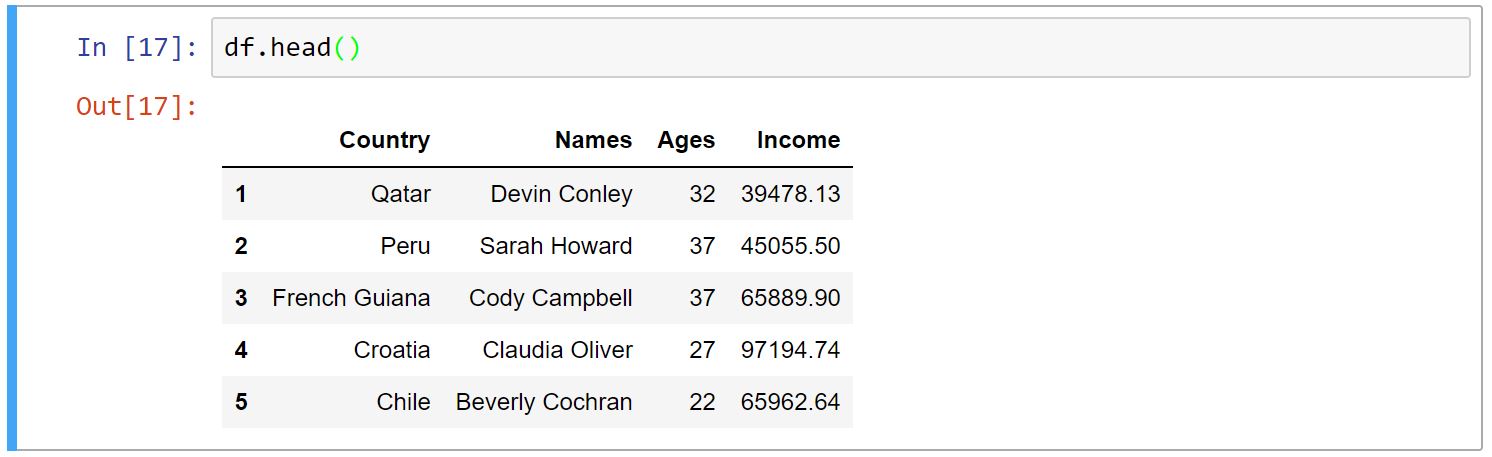
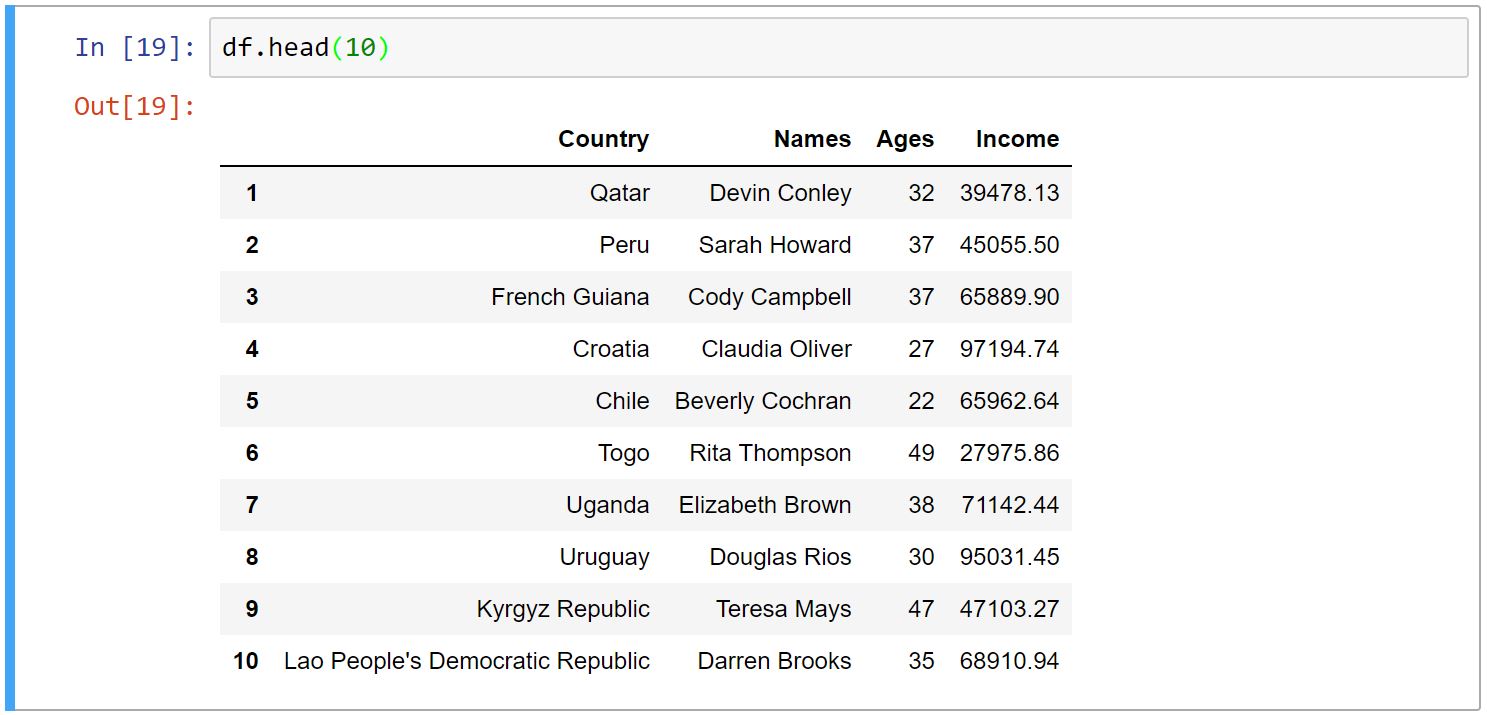
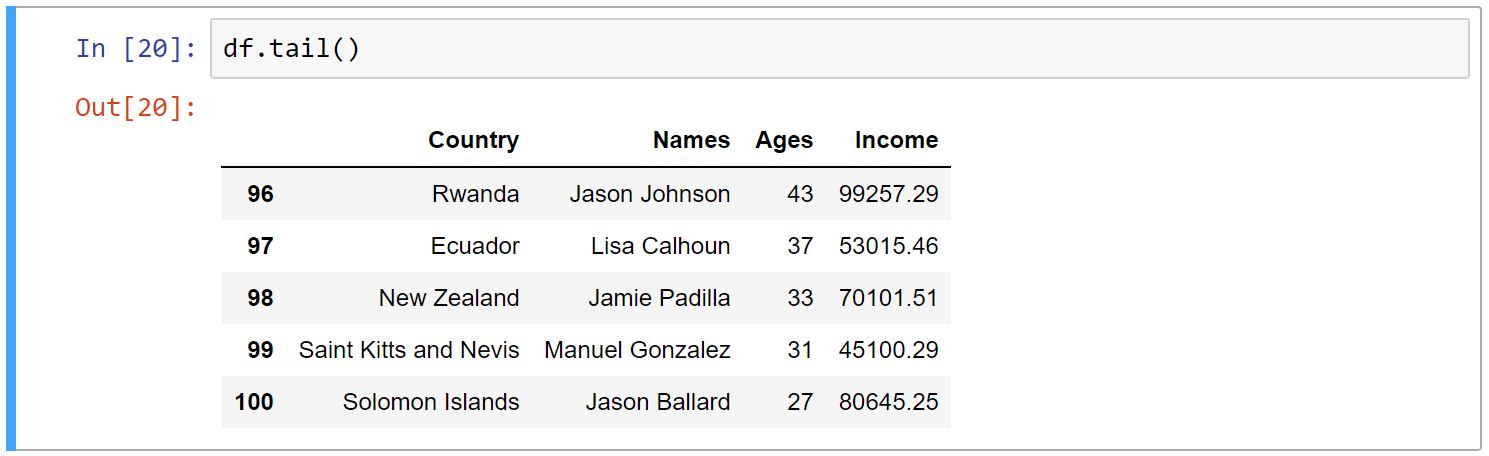
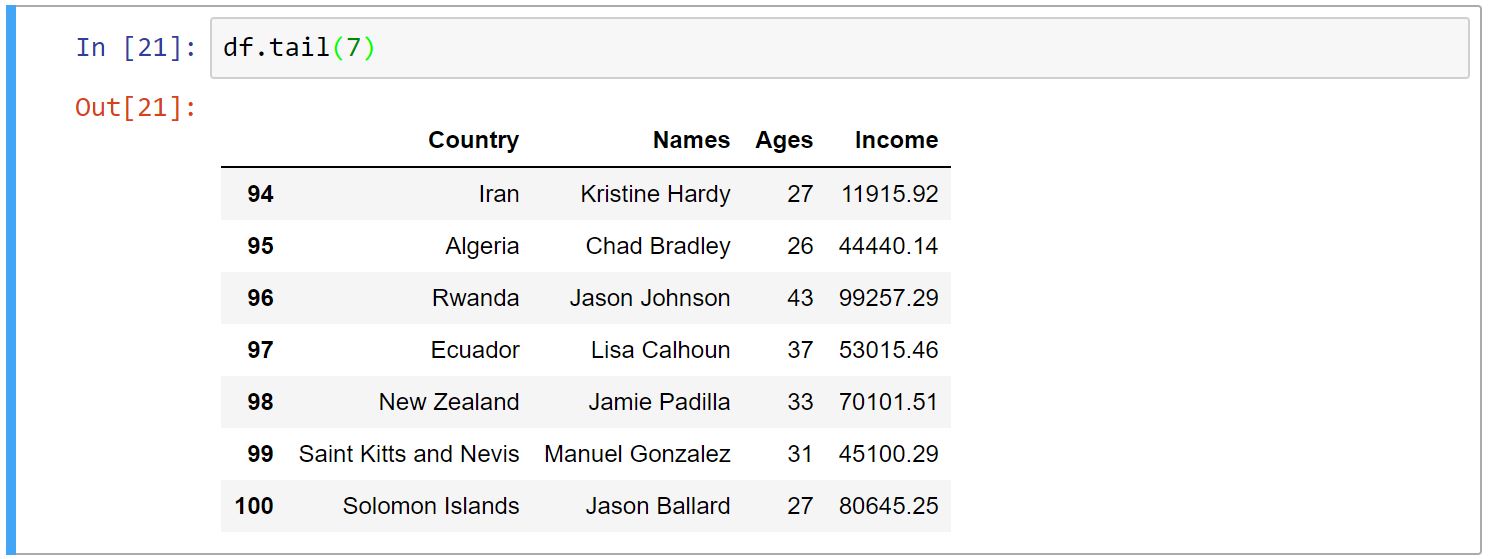
-
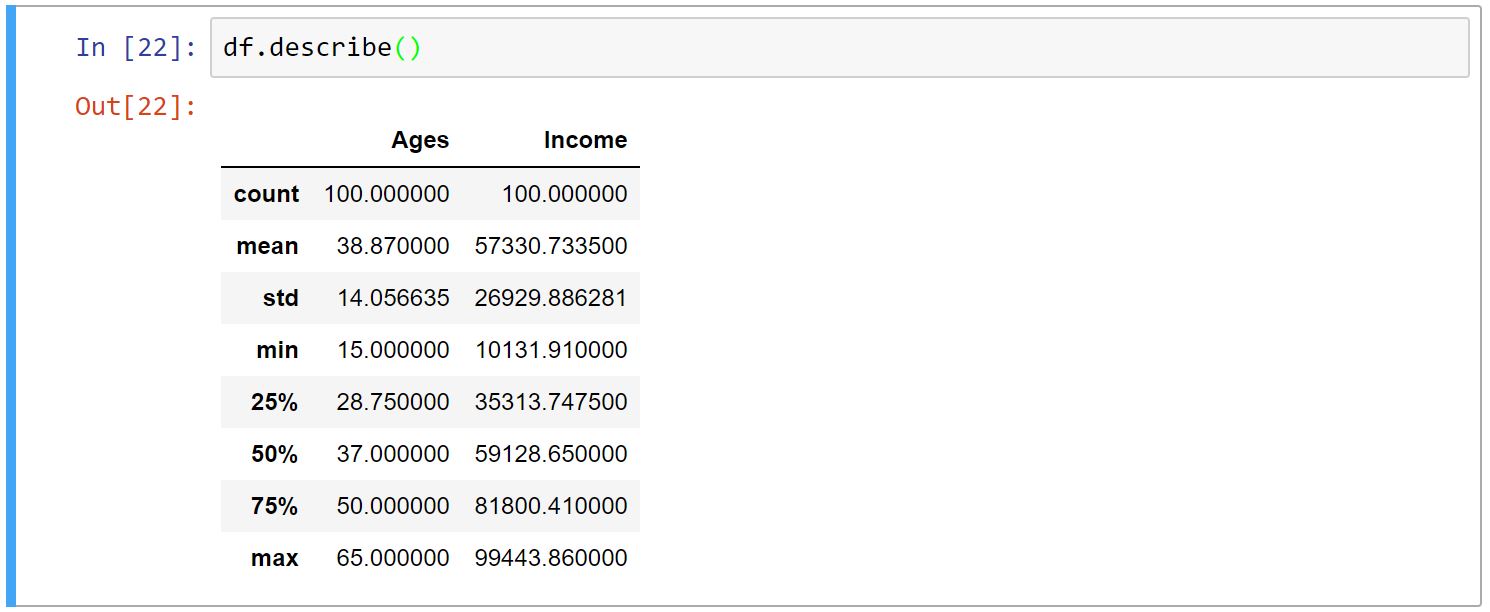
Describe
این تابع خلاصهای از اطلاعاتِ عددیِ DataFrame را به ما میدهد:
-
Shape
ابعادِ DataFrame را نشان میدهد.

-
Index
index-ها را نمایش میدهد.

-
Count
ستونها و تعداد نمونههای آن را نشان میدهد.

-
Columns
لیستی از ستونها را نمایش میدهد.

عملیات بر روی DataFrame
-
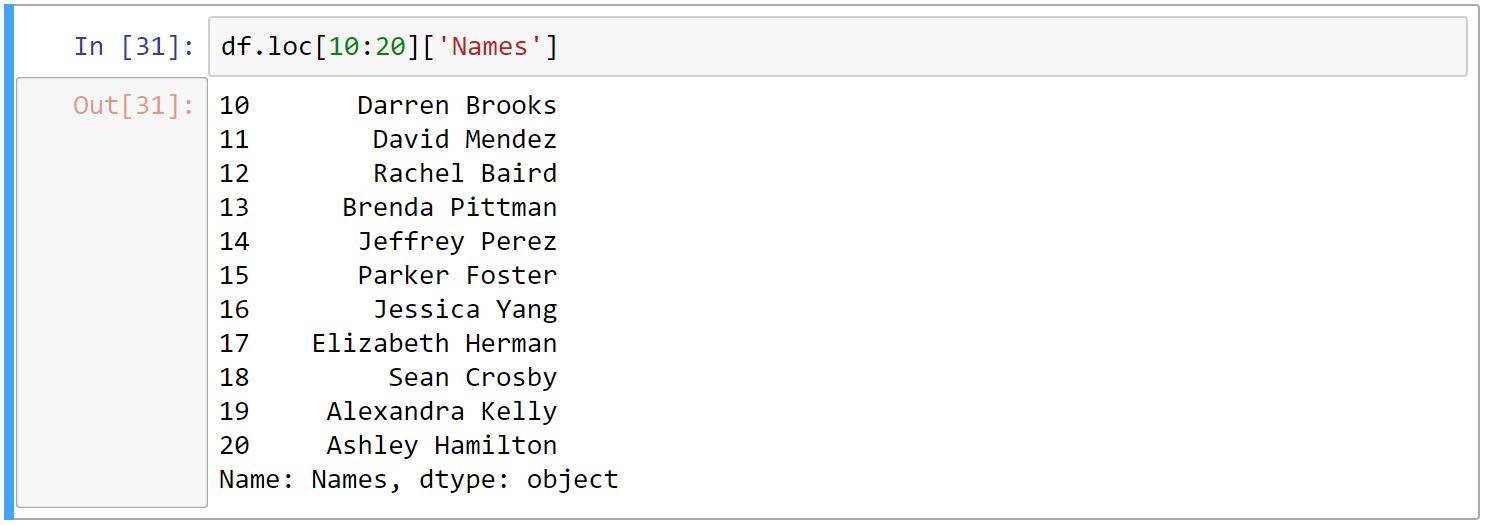
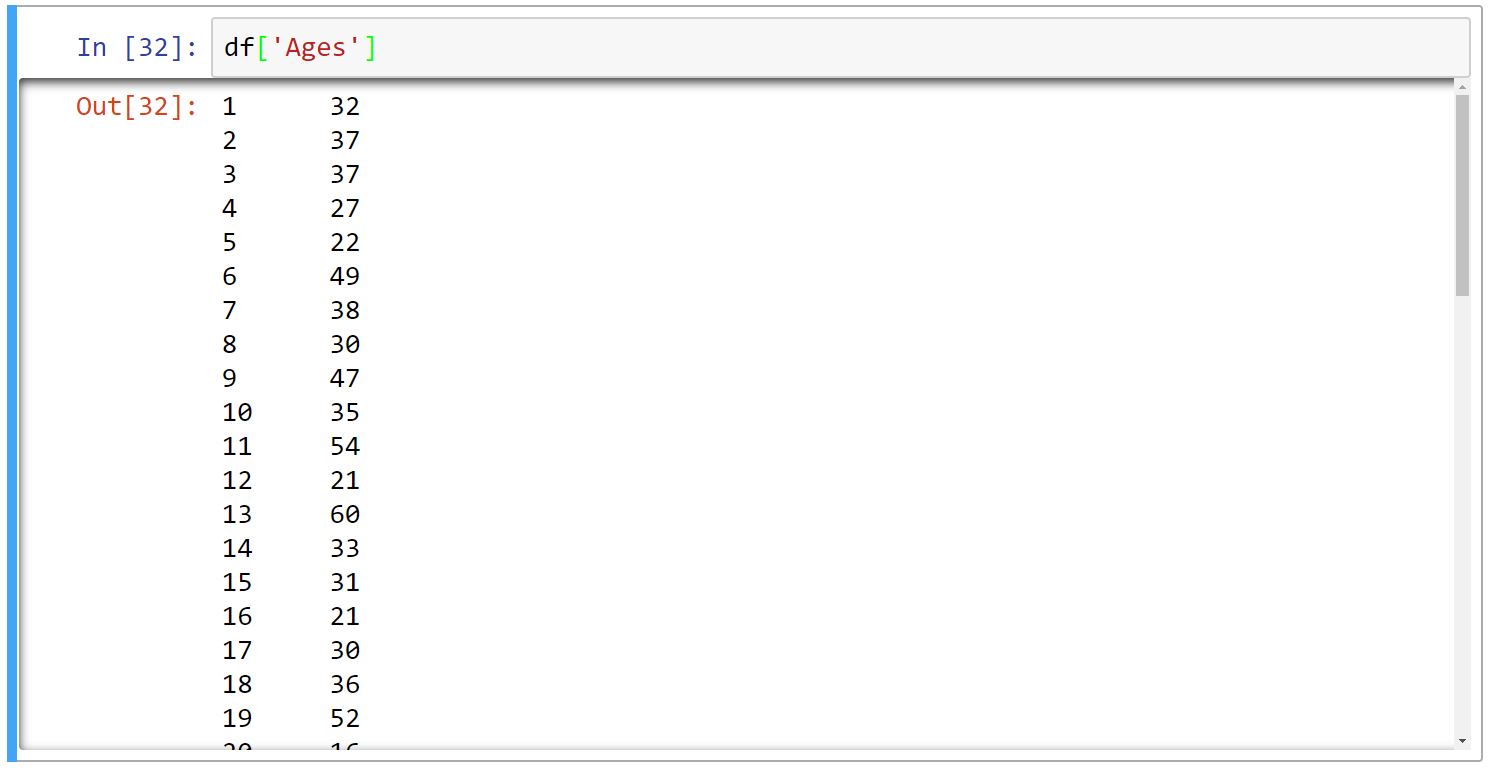
انتخاب سطر و ستون
برای انتخاب سطر از iloc و loc و برای ستون، از روش گرفتنِ مقدار توسطِ کلید در دیکشنری استفاده میکنیم.
تفاوت loc و iloc در اینجاست که به iloc عددِ index پیشفرض را میدهیم که همیشه از صفر شروع میشود، ولی به loc عددِ index-ی که خودمان تعریف کردیم را میدهیم (که در اینجا از ۱ تا ۱۰۰ میباشد)




-
اضافه کردن سطر و ستون
برای اضافه کردن سطر از loc استفاده میکنیم و index خود را به آن میدهیم. در نهایت مقادیرِ آن را به صورت لیست به آن میدهیم:
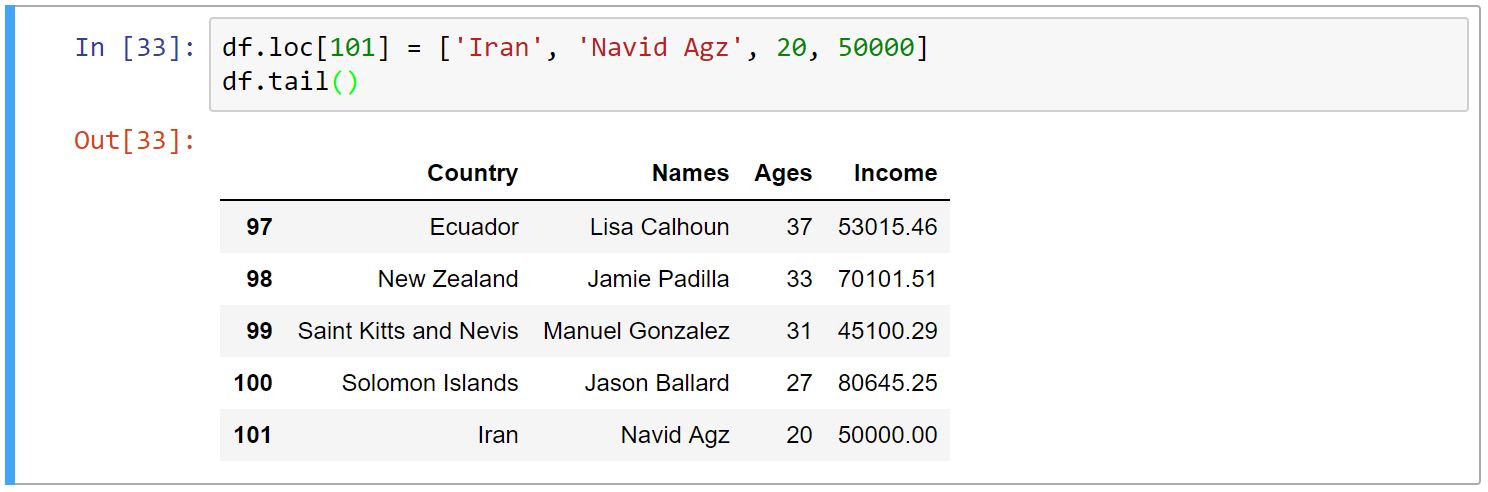
در نظر داشته باشید که تعداد و نوعِ elemnt-های لیستی که میدهیم، باشد مطابق با ستونها باشد.
اگر مقداری که به loc میدهیم تکراری باشد و مشابه آن را در DataFrame داشته باشیم، مقادیری که به آن داده شده، جایگزینِ مقادیر قبلی میشود.
برای اضافه کردن ستون به DataFrame، اسم ستون را به همراه مقادیرِ مورد نظر مانند دیکشنری وارد میکنیم:
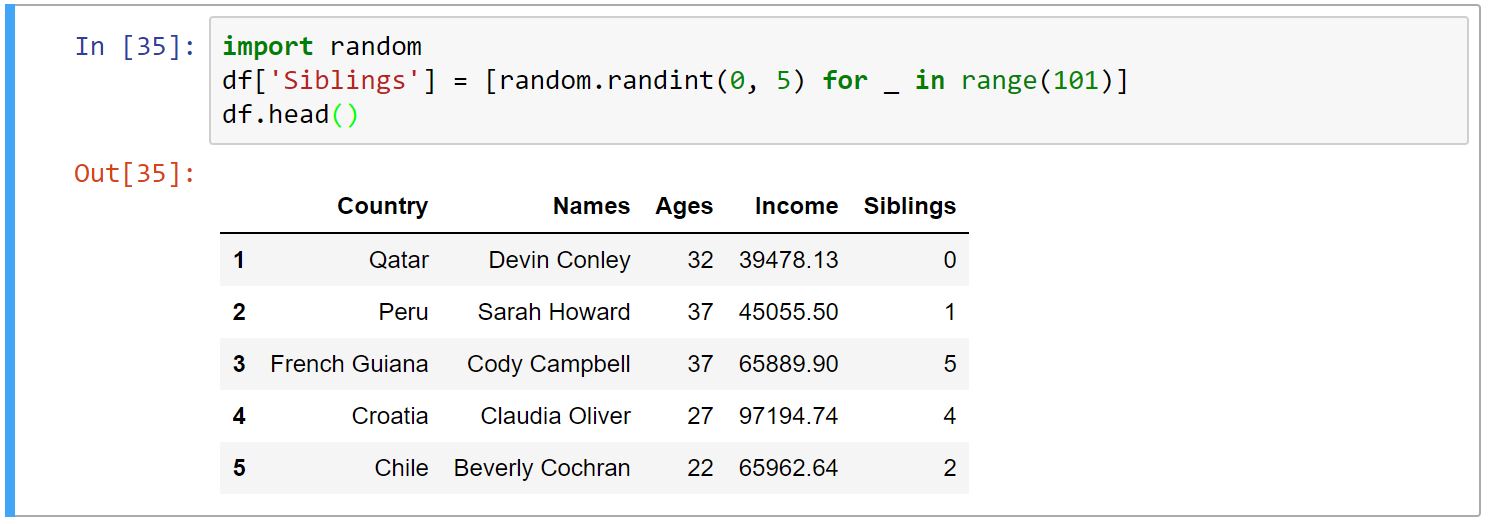
توجه داشته باشید با دادن مقدار تکراری، مقادیر آن ستون جایگزین میشوند.
-
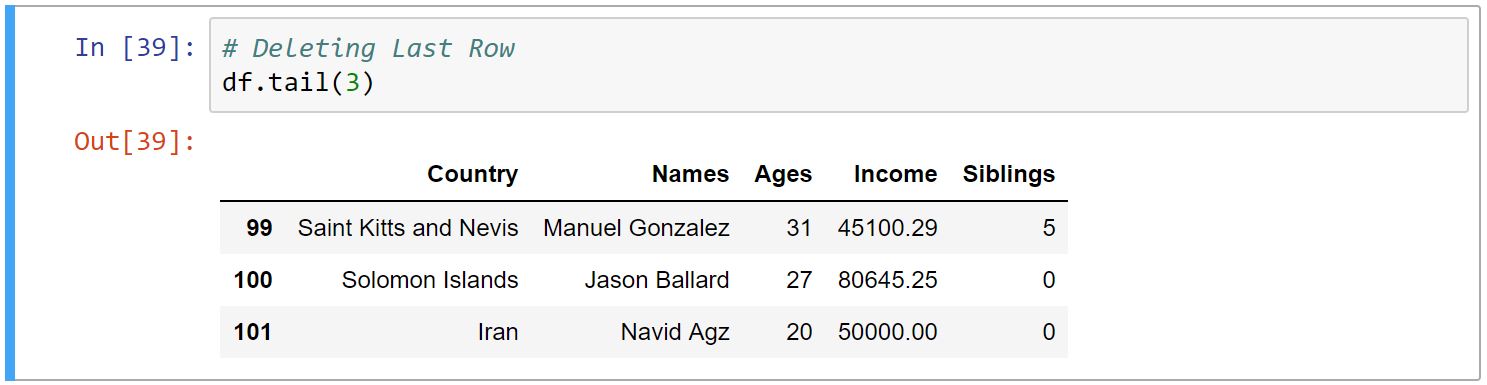
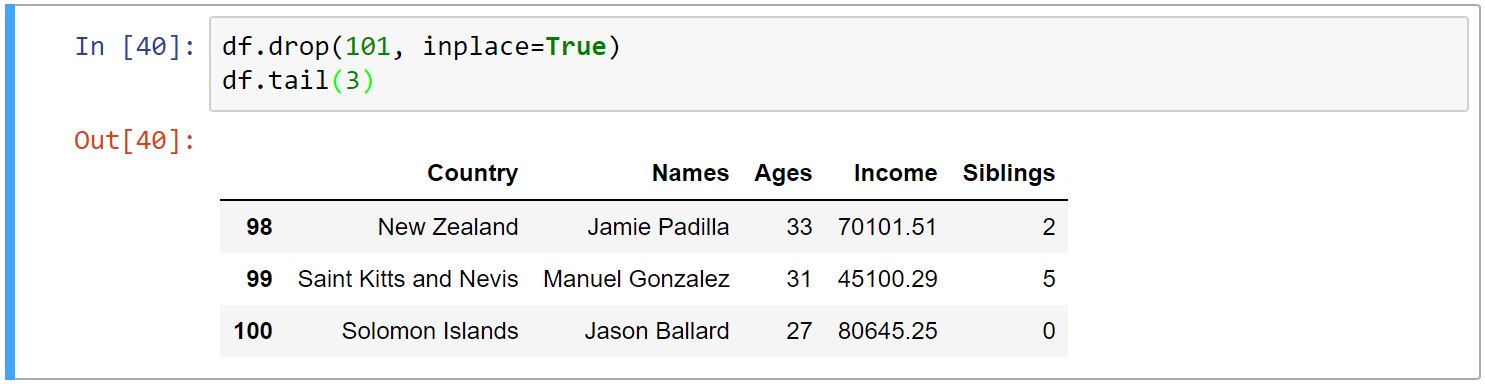
حذف سطر و ستون
برای حذف سطر و ستون از متد ()drop استفاده میکنیم. متدِ drop آرگومانهای مختلفی میگیرد، که پرکاربردترینِ آن اولین آرگومان است، که سطر یا ستون مورد نظر ماست. آرگومان دیگر axis است که برای سطر ۰ و برای ستون ۱ میباشد (به صورت پیشفرض ۰ است.) آرگومان بعدی inplace است، که در صورت True بودن تغییرات به همان DataFrame اعمال میشود (به صورت پیشفرض ۰ است که مواقعی استفاده میشود که بخواهیم تغییرات را در DataFrame جدید ذخیره کنیم.)
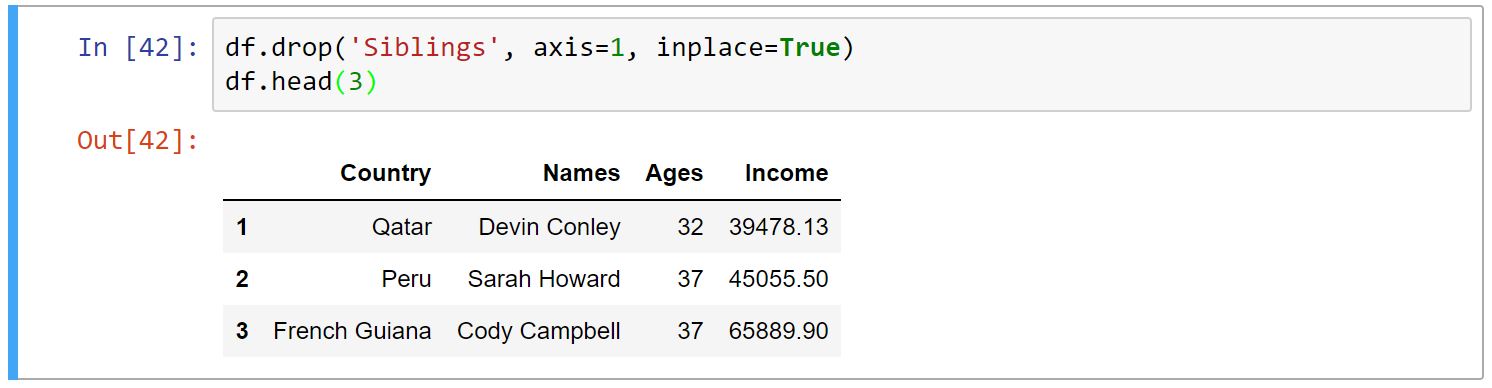
-
تغییر نام ستون
برای تغییر نام ستون از متد ()rename استفاده میکنیم. متد rename یک دیکشنری به عنوان آرگومان میگیرد، که کلیدهای آن نامِ فعلی ستونهاست و مقادیرِ آن، اسامیِ جدید است.
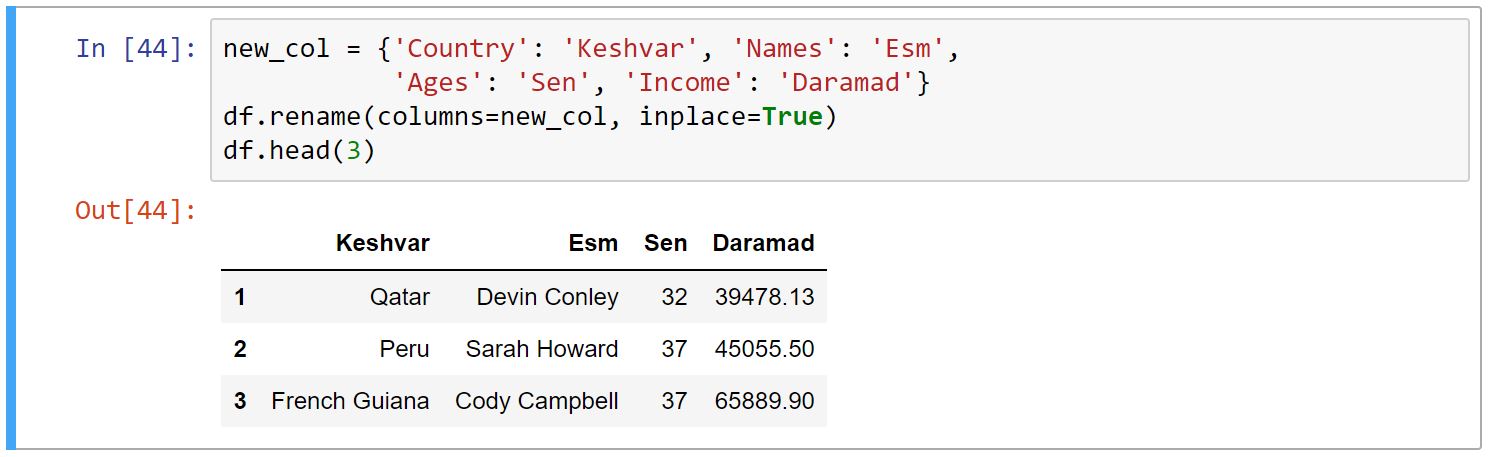
-
جایگذاری مقادیر با مقادیرِ دیگر
از متد replace برای جایگذاری استفاده میکنیم. این متد دیکشنری به عنوان آرگومان میگیرد، که کلیدهای آن نامِ فعلی مقادیر است و مقادیرِ دیکشنری، مقادیر جدیدی است که میخواهیم به آنها تغییر کنند.
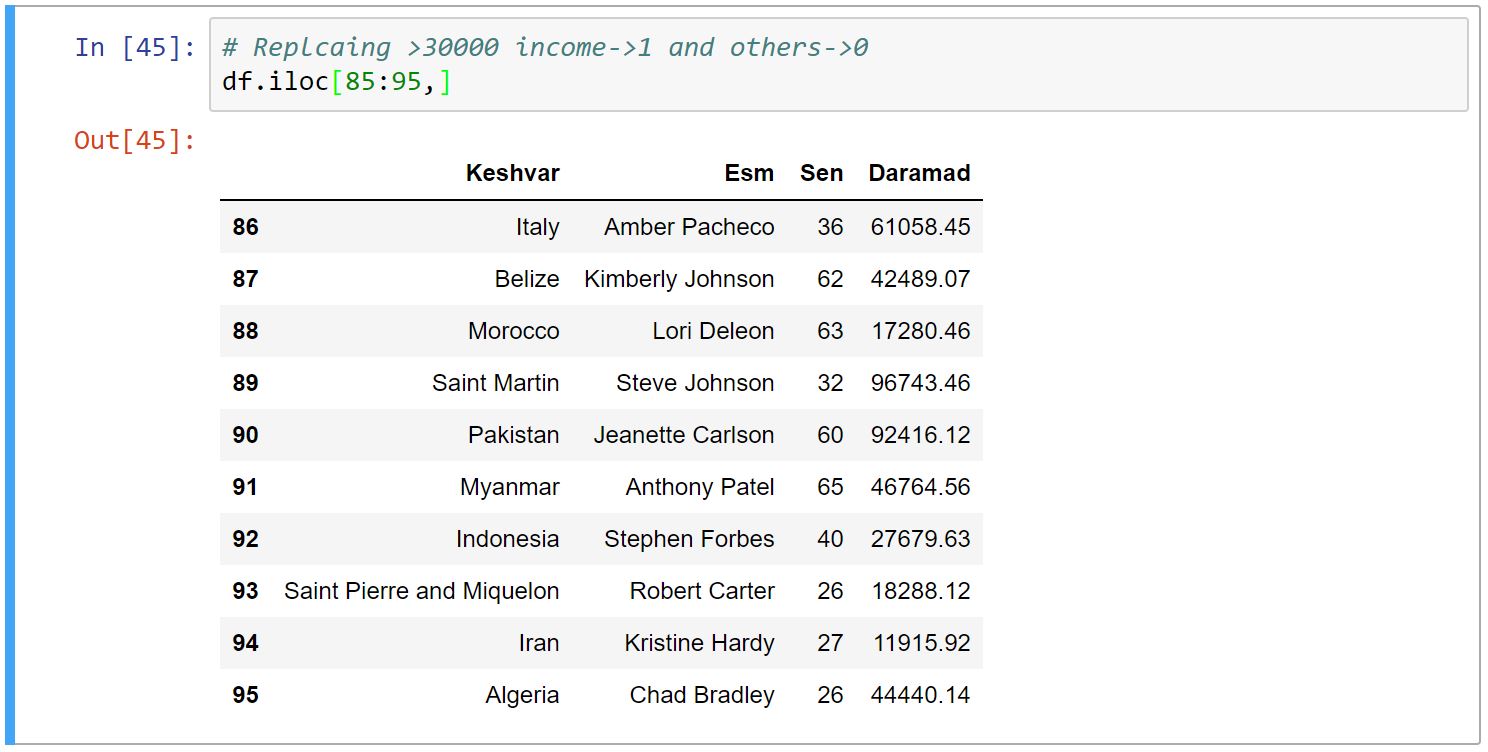
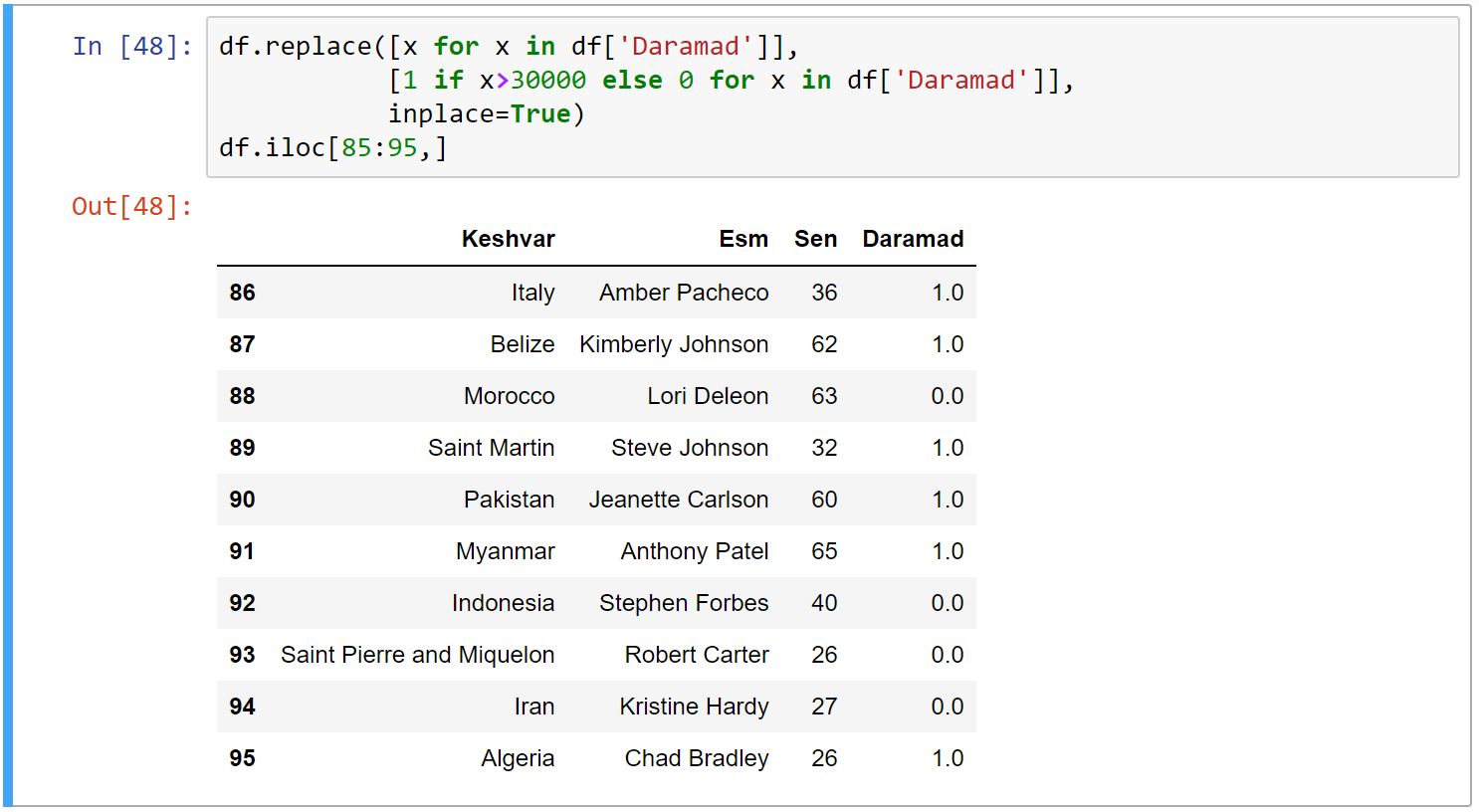
در این مثال با استفاده از list comprehension درآمدهای بالای ۳۰۰۰۰ را با ۱ و درآمدهای پایین ۳۰۰۰۰ را با ۰ جایگزین کردیم.
-
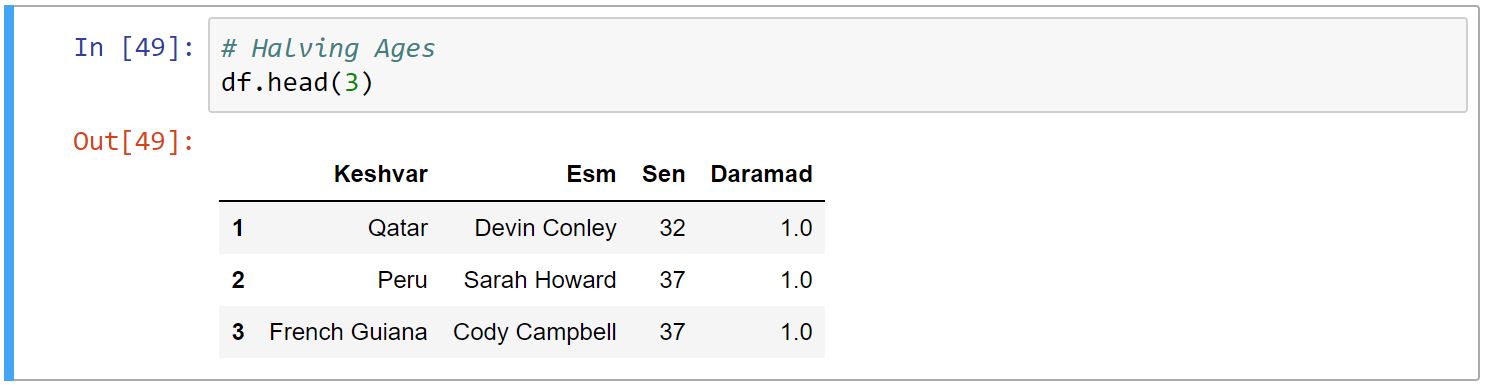
اعمال همگانیِ تابع بر روی سطر یا ستون
برای اعمال همگانی عملی خاص از تابع apply استفاده میکنیم. برای مثال در کد زیر سن تمامی افراد را نصف کردیم.
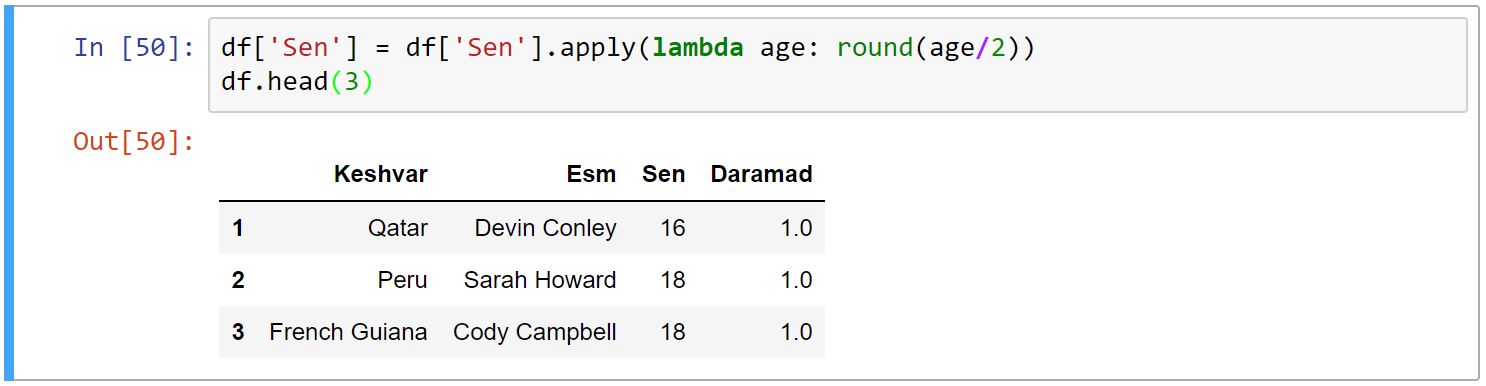
توصیه میشود به جای استفاده از for برای پیمایشِ DataFrame، از apply به دلیل سرعت بیشتر استفاده شود.
-
ذخیره DataFrame
میتوان با دستور زیر DataFrame خود را به صورت csv ذخیره کنید:
df.to_csv('myDataFrame.csv')
و با دستور زیر فایل csv را بخوانید:
df = pd.read_csv('myDataFrame.csv')
و حتی به صورت excel ذخیره کرد و خواند:
# Writing Excel
writer = pd.ExcelWriter('myDataFrame.xlsx')
df.to_excel(writer, 'DataFrame')
writer.save()
# Reading Excel
xls_file = pd.ExcelFile('myDataFrame.xlsx')
فایل تمام کدهای نوشته شده، در این لینک در دسترس است.
در این مقاله سعی شد به تمامی توابع و عملیاتهای pandas پرداخته شود. همچنین میتوانید برای توضیحات تکمیلی از documentation اصلی pandas هم استفاده کنید. استفاده عمده pandas در تمیز و نرمال کردنِ دادههاست که با تمرین و تکرار به کارامد بودنِ این ابزار در این حوزه پی خواهید برد.
مطالب زیر را حتما مطالعه کنید

آشنایی با توابع در پایتون

راه اندازی Django به همراه Postgresql، Nginx و Gunicorn

آشنایی با حلقه ها در پایتون

آشنایی با رشته در پایتون

برنامه نویسی چند نخی در پایتون

تولید اعداد Random با Python
2 Comments
Join the discussion and tell us your opinion.
دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.
ممنون دوستان
سپاس.